(plan-it) 리밸런싱 배치 최적화
plan-it 프로젝트의 상품 추천 배치를 구현하고 최적화 하는 과정을 기록합니다.
Stack : Srping Boot, MyBatis, MySQL, Spring Batch
기능 개요
리밸런싱 (Rebalancing)이란?
리밸런싱은 투자 초기 설정한 자산별 비중을 유지하기 위해 포트폴리오 내 자산의 비중을 재조정하는 것을 의미합니다.
만약 초기에 투자 포트폴리오가 A주식(60%), B주식(40%)였고, 수개월 후 현재 자산이 A주식(80%), B주식(20%)으로 변동 되었을때 많이 오른 자산은 일부 수익을 실현하고, 하락한 자산은 다시 낮은 가격에 매입하여 처음에 의도한대로 포트폴리오를 관리합니다.
리밸런싱은 대부분 수익의 극대화 보다는 포트폴리오의 리스크를 관리하기 위함이라고 합니다.
📍 직접 재정의해본 리밸런싱
Plan-IT 서비스에서는 초기에 사용자가 목표에 할당했던 자산 비율을 맞추기 위해서 상품을 변경하거나 매수/매입 하는 과정을 시뮬레이션 하고, 단순히 자산의 비율을 재조정하는 것을 넘어서 교체가능한 투자 상품을 투자 성향에 맞게 추천해주는 레포트를 생성하는 기능을 개발했습니다.
비즈니스 로직
사용자의 목표 상의 비중, 현재 자산을 조회하여 비중 확인
초기 비중과 맞도록 조정할 자산 계산
ETF 상품들의 1달동안의 상품 성향(
안정형,공격형등)별로 가장 높은 수익율을 보이는 상품을 조회2-1. ETF 상품별 최근 1달간의 수익률을 측정 선행 필요
2-2. 사용자의 성향과 일치하는 상품만 추천 ( 관련규정 )
가장 수익률이 높은 ETF 상품으로 교체하고 비율 맞추기
DB에 목표별로 레포트 저장
상황
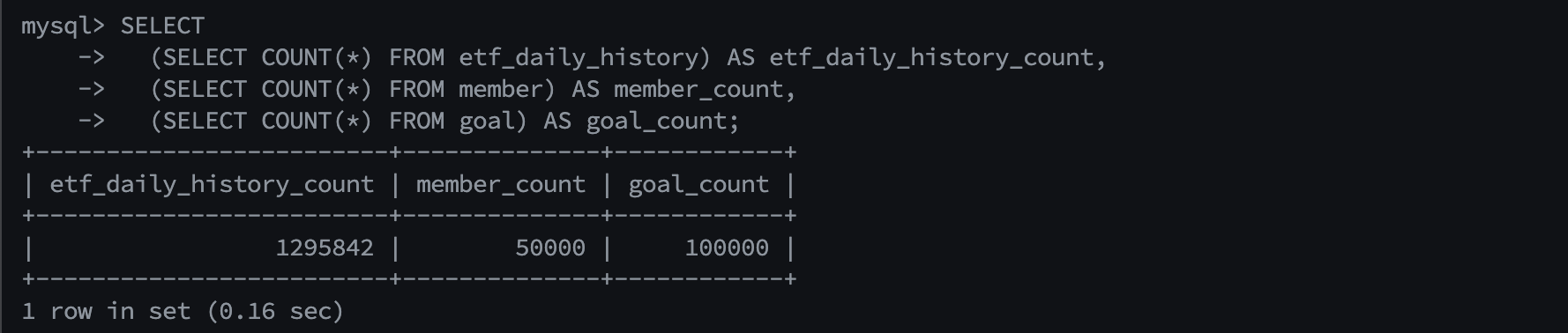
50,000명의 사용자에 대한 목표, 등 모든 목데이터 생성 및 실제 ETF 상품의 일일 매매 정보를 공공데이터에서 주기적으로 저장하여 100만개의 데이터가 MySQL에 적재되어 있었습니다.
etf_daily_history, member, goal 개수 (goal은 사용자가 설정한 목표 - 사용자별로 2개씩 존재)
구현 문제점
시간이 오래 걸린다.
구현을 완료하고 배치를 실행시키고 보니 5만건의 사용자에 대해서 1시간 30분 정도 시간이 소요되는 것을 확인했습니다.
시스템에서 daily 배치가 14건 실행되고 있었고 새벽시간 동안 레포트를 생성하기 위해서는 더 짧은 시간내에 배치가 완료되어야 했습니다.

1. Database Query 시간 체크
Database의 쿼리 시간을 확인해봤습니다.
최근 1달간의 ETF history 조회를 위해서 사용한 쿼리
1
2
3
4
5
-- 특정 상품(shorten_code로 식별)의 특정 시점 이후의 매매 정보를 가져오는 쿼리
SELECT *
FROM etf_daily_history
WHERE shorten_code = #{shortenCode}
AND base_date > #{startDate}
간단한 쿼리지만 매일 KRX(한국 거래소)에서 ETF 매매 정보 약 1,000건이 누적되어 저장되므로 앞으로 많은 양이 저장될 것입니다.
실제 batch에서 etf 매매내역 조회시 사용되는 쿼리의 조회시간이 1sec정도 되는걸 확인했습니다.

MySQL의 내부 캐시로 인해서 항상 조회하는데 1초가 걸리진 않겠지만, 처음 접근하는 매매내역은 항상 1초씩 걸릴 것이라고 생각하면 많은 시간이 소요될 것입니다.
2. 싱글 스레드의 한계
스프링 배치의 공식문서를 보면 기본적으로 배치 프로세스 job을 수행하는 스레드가 단일 스레드라고 되어 있습니다. ( 공식문서 )
50,000명의 유저를 하나의 스레드가 매번 DB 조회 -> 시뮬레이션 비즈니스 로직 -> DB 저장의 로직을 거치면서 순회하는 상황이었습니다.
1시간 30분(=5400sec)에 100,000건의 목표에 대해서 리밸런싱과 상품 추천이 이루어지므로
–> 100,000 / 5400 = 18TPS
Batch서버를 분리까지 했는데도 너무 낮은 TPS를 보여주었습니다.
[배치 실행중 모니터링]
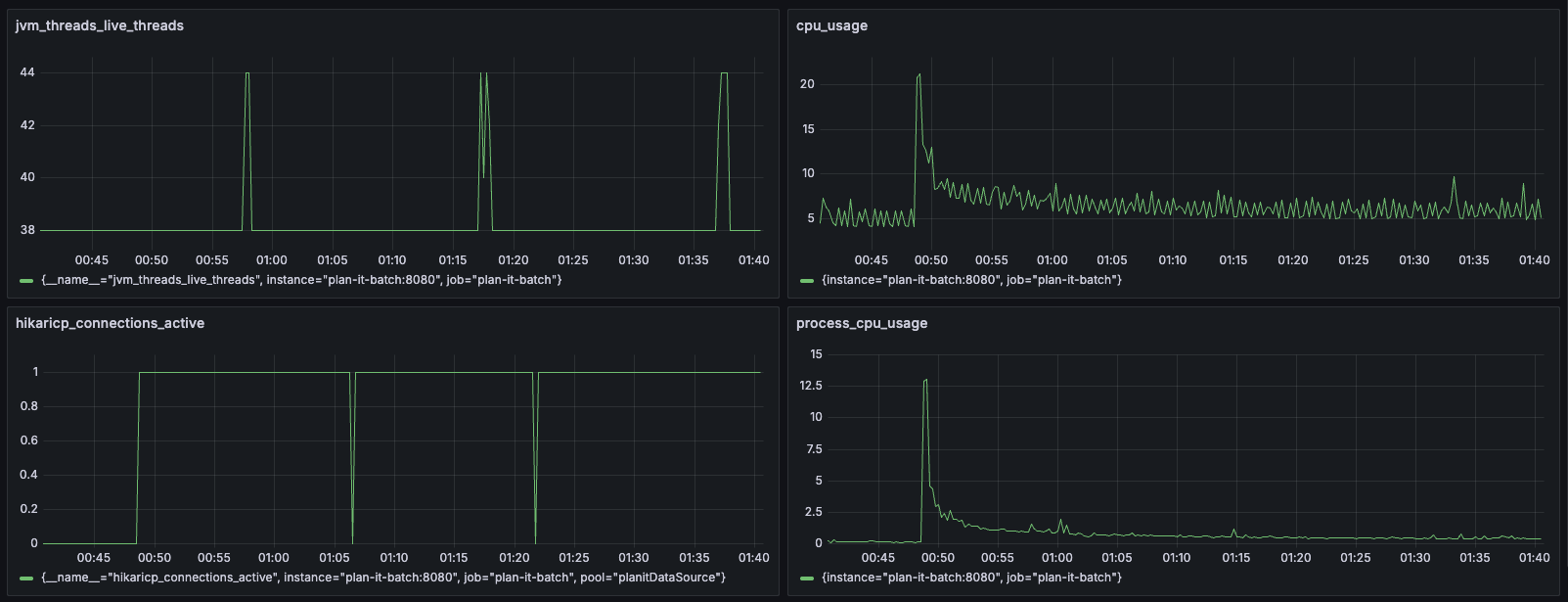
배치 수행중 모니터링을 통해설 리소스를 어떻게 사용하고 있는지 prometheus와 grafana를 통해 확인해봤습니다.
hikari_connections_active를 보면 DB 커넥션 풀도 1개 밖에 사용하지 않고 있었고, cpu 사용률도 배치 진행중에도 낮은 사용률을 보여주었습니다. 여유로운 리소스를 최대한 활용할 필요가 있음을 느꼈습니다.
최적화 - 병렬처리
위와 같이 시간이 오래걸리는 원인들을 파악했고 이를 개선하기 위해 다음과 같은 방법들을 사용하였습니다.
1. 스레드풀 생성 및 배치 병렬 처리
여러 스레드가 동시에 병렬로 배치를 처리하게 하여 스레드별로 작업량을 줄여 빠르게 처리할 수 있도록 구성했습니다.
이를 위해서 Thread pool을 구성하고 각 스레드별로 처리할 범위를 나눠주는 작업이 필요했습니다.
1
2
3
4
5
6
7
8
9
10
11
@Bean
public ThreadPoolTaskExecutor batchTaskExecutor(MeterRegistry registry) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(4);
executor.setMaxPoolSize(4);
executor.setQueueCapacity(16);
executor.setThreadNamePrefix("batch-executor-");
executor.initialize();
return executor;
}
총 4개의 스레드 풀을 5개로 잡은 이유는
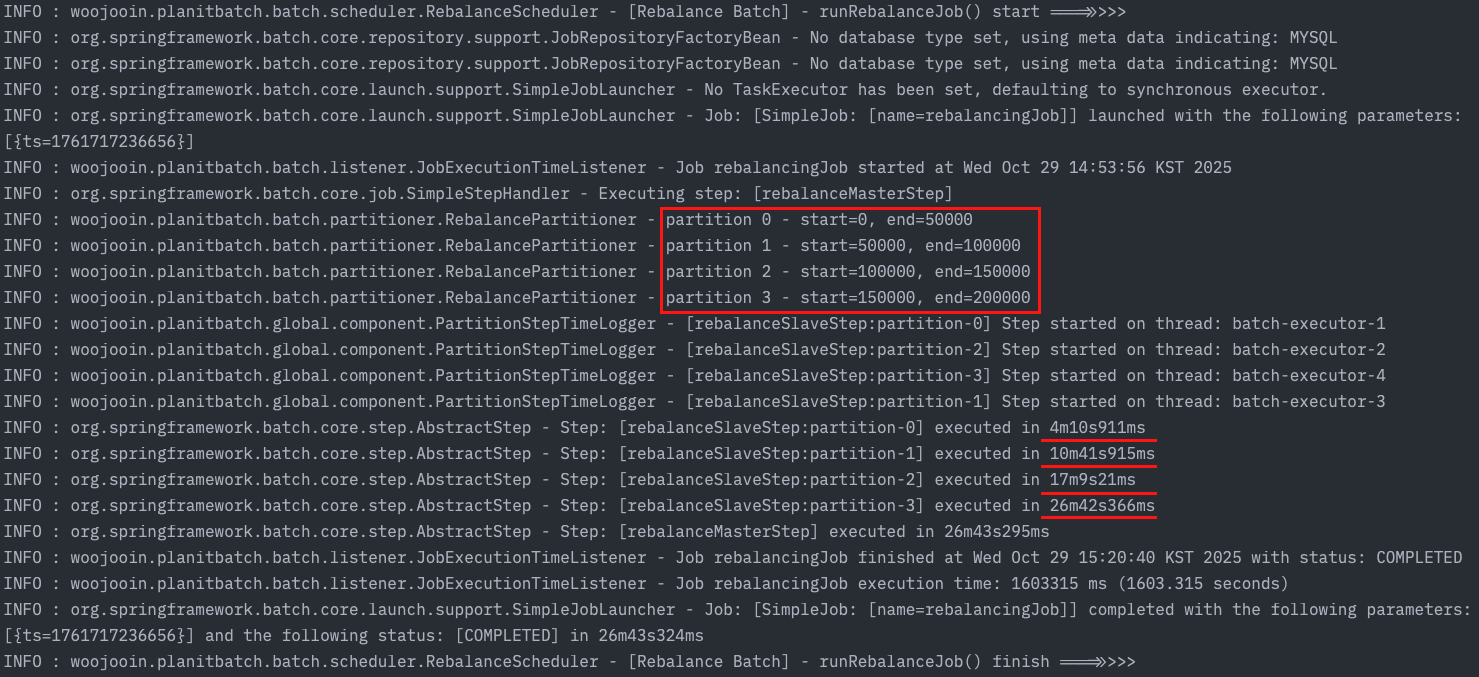
1-1. 데이터 파티셔닝 (offset)
스레드별로 데이터를 나눠주기 작업할 데이터에 대해서 적절한 크기로 나누어 할당해주어야 합니다.
Offset 기반의 페이지네이션을 활용하면 데이터가 가변적인 상황에도 균등하게 분할하고 나눌 수 있습니다.
작업 대상은 “사용자가 설정한 목표별로 할당된 사용자가 소유한 자산들의 조합“이었습니다.
다음과 같은 쿼리로 작업할 데이터의 크기를 조회하고 (data size) / (thread_pool_size)의 크기만큼 각 스레드에 startOffset endOffset을 할당해주었습니다.
1
2
3
4
5
6
7
8
SELECT count(*)
FROM goal AS g
JOIN action AS a
ON a.goal_id = g.goal_id
JOIN member_product AS mp
ON mp.member_product_id = a.member_product_id
JOIN product AS p
ON mp.product_id = p.shorten_code
[RebalancePartitionor.java 파티셔너 구현 코드]
Spring Batch의 Partitioner 를 통해 스레드별로 컨텍스트에 파라미터로 파티셔닝을 해줄 수 있습니다. ( 참고 링크 )
각 스레드별로 ExecutionContext에 startOffset, endOffset을 넣고 Partitioner를 구현했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
@Component
@RequiredArgsConstructor
public class RebalancePartitioner implements Partitioner {
private final BalanceRepository balanceRepository;
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
int total = balanceRepository.countAll();
int targetSize = (int)Math.ceil(total / (double)gridSize);
Map<String, ExecutionContext> result = new HashMap<>();
int start = 0;
for (int i = 0; i < gridSize; i++) {
int end = Math.min(start + targetSize, total);
ExecutionContext context = new ExecutionContext();
context.putInt("startOffset", start);
context.putInt("endOffset", end);
result.put("partition-" + i, context);
start = end;
}
return result;
}
}
[RebalanceReader.java]
offset별로 청크 크기만큼 읽는 ItemReader 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
@Component
@StepScope
@RequiredArgsConstructor
public class RebalanceReader implements ItemReader<Balance> {
private final BalanceRepository balanceRepository;
@Value("#{stepExecutionContext['startOffset']}")
private Integer startOffset;
@Value("#{stepExecutionContext['endOffset']}")
private Integer endOffset;
private int nextOffset = -1;
private int cursorInPage = 0;
private List<Balance> currentList = Collections.emptyList();
public static int CHUNK_SIZE = 50;
@Override
public Balance read() {
if (nextOffset == -1) {
nextOffset = startOffset;
}
if (nextOffset >= endOffset) {
return null; // 내 파티션 범위 끝
}
// 현재 페이지 다 읽었으면 새로 로드
if (cursorInPage >= currentList.size()) {
int remaining = endOffset - nextOffset;
int pageSize = Math.min(RebalanceReader.CHUNK_SIZE, remaining);
currentList = balanceRepository.findBalancePanging(nextOffset, pageSize);
cursorInPage = 0;
if (currentList.isEmpty()) {
return null;
}
}
Balance item = currentList.get(cursorInPage++);
if (cursorInPage >= currentList.size()) {
nextOffset += currentList.size();
}
return item;
}
}
배치 실행 결과
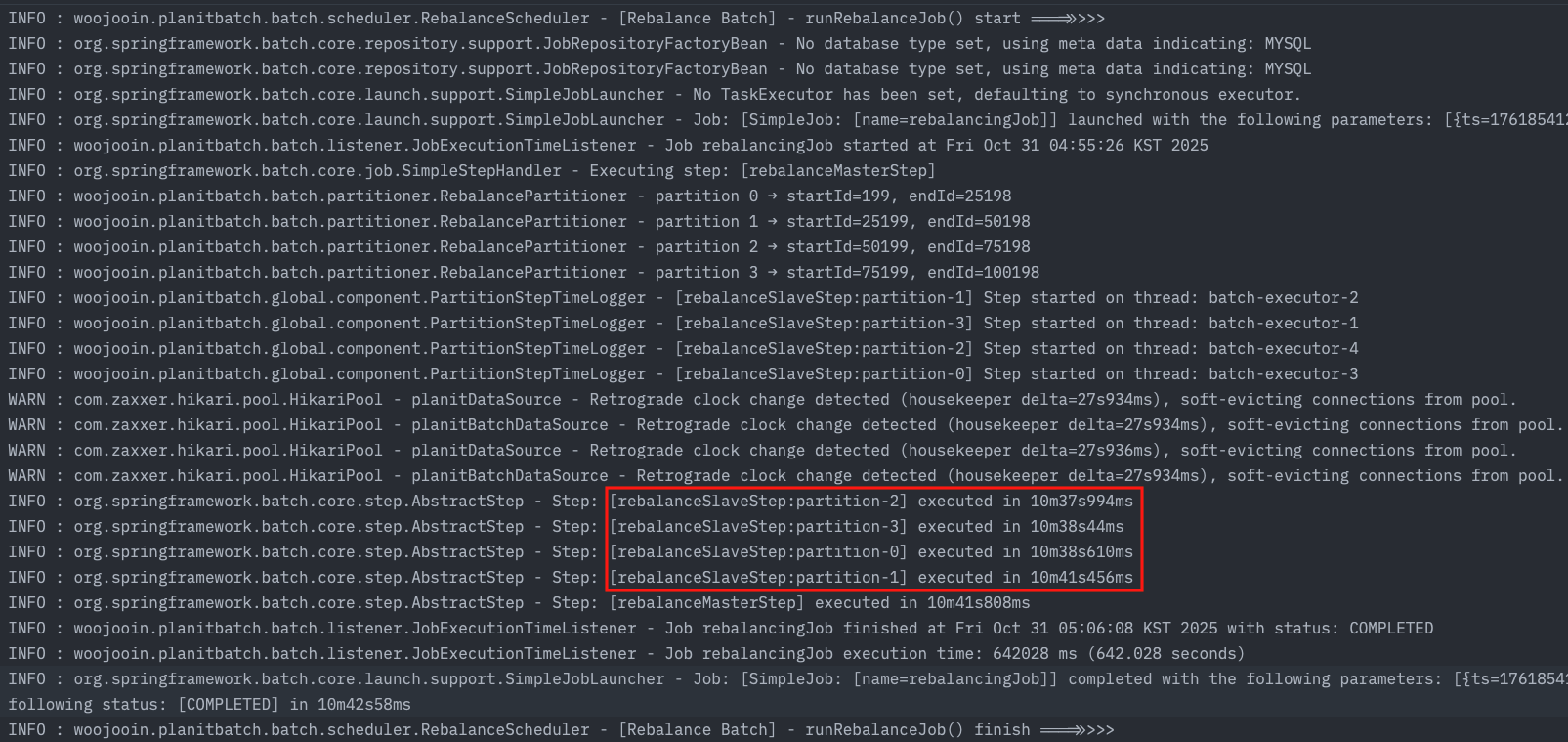
각 파티션별로 작업이 균일하게 나뉘어 할당된 것을 확인했습니다.
결과적으로 총 26분으로 상당 시간이 줄어든 것을 확인할 수 있습니다.
⚠︎ 문제 발생
But,,
로그를 보면 파티션별로 시작시간과 작업 크기는 동일했지만 작업 진행 시간이 크게 차이나는 것을 볼 수 있습니다.
| partition | Time |
|---|---|
| Partition-0 | 4m10s |
| Partition-1 | 10m41s |
| Partition-2 | 17m09s |
| partition-4 | 26m42s |
프로메테우스로 확인해본 스레드와 커넥션풀
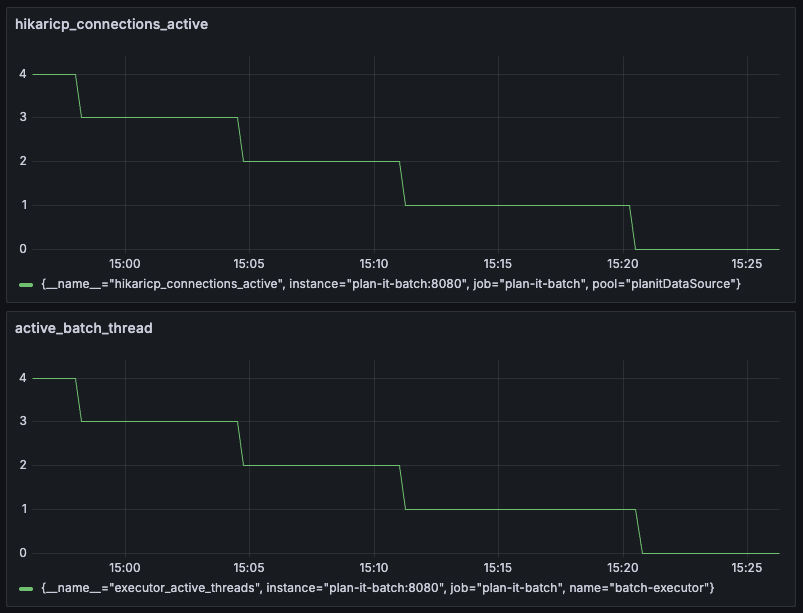
스레드별로 종료 시점과 DB 커넥션풀 점유 종료 시간이 동일한 양상을 보였습니다.
DB에서 읽기 쓰기시간이 다르게 걸렸다는 것을 알 수 있었습니다..
그렇다면 원인은 무엇일까요?
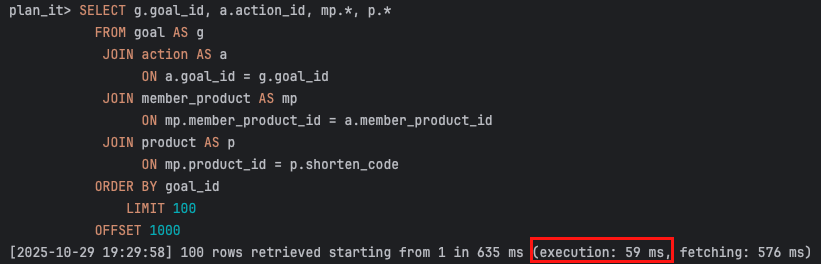
partition-0와 partition4의 쿼리비교를 진행해보았습니다.
partition-0
partition-3
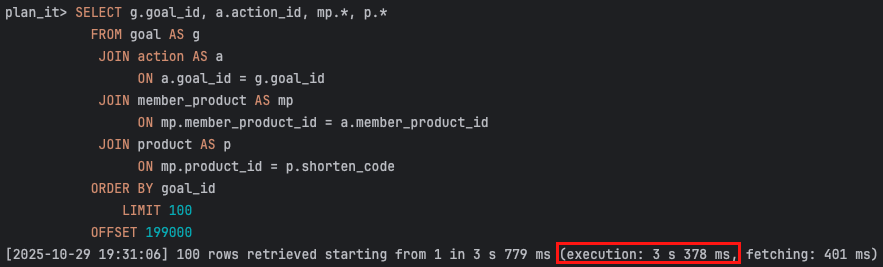
partition-0 범위의 오프셋은 59ms 밖에 안걸렸는데 partition-3의 경우에는 굉장히 3s 378ms 로 굉장히 오래 걸리는 모습을 보여줍니다.
이런 차이가 나는 이유는 Offset 기반의 조회를 진행할때 MySQL은 다음과 같은 과정을 통해 결과를 반환하기 때문입니다.
- 인덱스를 따라 순차적으로 스캔하면서 결과를 임시 버퍼에 저장
OFFSET에 해당하는 개수만큼 스킵(drop)LIMIT개수만큼만 최종 반환
즉, OFFSET이 커질수록 MySQL이 읽고 버려야 할 행(row)의 수가 기하급수적으로 증가합니다.
이 상황을 방치한다면 데이터가 쌓일수록 특정 파티션의 배치 시간은 증가할 것이고 지속가능한 시스템이 아니라고 판단했습니다.
1-2. 데이터 파티셔닝 개선 (cursor)
특정 오프셋의 범위까지 풀스캔을 하지 않기 위해서는 B-Tree 내부에 정렬되어 있는 즉 indexing 되어있는 값을 기준으로 조회한다면, 어떤 범위의 값을 조회하던 동일한 시간을 기대할 수 있습니다.
이를 위해서 커서기반 페이지네이션을 고려했습니다.
커서기반의 페이지네이션을 고려한 이유
커서기반과 오프셋 기반의 페이지네이션을 비교해보겠습니다.
| 구분 | Offset 기반 | Cursor 기반 |
|---|---|---|
| 동작원리 | 조건범위까지 탐색후 앞부분을 버리고 반환 | 클라이언트에서 이전 요청의 마지막 id를 기억, where id > :id 로 조건부 탐색 |
| 대표 쿼리 | LIMIT 10 OFFSET 1000 | WHERE id > :lastId LIMIT 10 |
| 기준 | 데이터의 물리적 위치(index) | 특정 데이터의 고유 식별자(cursor) |
| 정렬 기준 | OFFSET 순서 | 커서 컬럼 기준 (ex: id, created_at 등) |
| 고려사항 | 없음 | 커서가 의존하는 컬럼 관리 필요 |
즉, Offset 기반과 달리 Cursor 기반 페이지네이션은 의존하는 컬럼이 인덱싱되어 있다면 빠른 탐색이 가능했습니다.
🧑💻 비즈니스적으로 잘 정의해보자
커서 기반 페이지네이션을 위해서는 현재 진행되는 배치의 특정 컬럼을 의존해야 합니다. 하지만 대상으로 하는 데이터가 복잡한 join을 사용한 쿼리를 통해 조회되었기 때문에 어떤 컬럼을 기준으로 할 것인가에 대한 비즈니스적 고민이 필요했습니다.
[기존 Offset 기반 조회 쿼리]
1
2
3
4
5
6
7
8
9
10
11
SELECT g.goal_id, a.action_id, mp.*, p.*
FROM goal AS g
JOIN action AS a
ON a.goal_id = g.goal_id
JOIN member_product AS mp
ON mp.member_product_id = a.member_product_id
JOIN product AS p
ON mp.product_id = p.shorten_code
ORDER BY goal_id
LIMIT #{chunk_size}
OFFSET #{offset};
위 join문에 결합되어 있는 테이블의 이해관계를 분해해보고 어떤 컬럼을 기준으로 하면 좋을지 고민해봤습니다.
비즈니스 로직과 ERD를 비교를 용이하게 하기위해 생성 시점과 연관관계를 아래와 같이 도식화했습니다.
아래는 도식화된 사용자의 목표와 자산 할당 방법입니다. ⤵️ ⤵️

위 도식화를 통해서 2가지 방법을 고려했습니다.
action테이블 PK전체 조회를 했을때 조회되는 ROW와 1:1로 대응되는 데이터는
action테이블이었습니다.
직관적으로 생각했을때 cursor 기반의 조회를 할때, 조회하는 데이터에 대해서 유니크한 값을 가지기 때문에 join 시 항상action을 중심으로 탐색 가능했기 때문입니다.
하지만action은goal생성 이후에 종속적으로 생성되는 데이터라, 커서를action단위로 이동할 경우 하나의goal에 속한 데이터가 중간에 잘리거나 중복 처리되는 문제가 발생했습니다.goal테이블 PK 📍위 도식화를 통해 Goal이 생성되는 시점 이후에 다른 테이블이 의존되어 값이 생성되는 것을 알 수 있었습니다.
goal은 사용자 포트폴리오의 상위 엔티티로, 하위 데이터(action,member_product,product)가 모두 이를 기준으로 생성됩니다.
따라서goal_id를 커서 기준으로 사용하면 배치 단위와 비즈니스 단위가 일치하고, 인덱스 기반 범위 탐색이 가능해져 성능과 일관성을 모두 확보할 수 있습니다.
최종 goal PK 기반 커서 기반 select 문
1
2
3
4
5
6
7
8
9
10
11
12
SELECT g.goal_id,
a.action_id,
mp.*,
p.*
FROM goal AS g
JOIN action AS a ON a.goal_id = g.goal_id
JOIN member_product AS mp ON mp.member_product_id = a.member_product_id
JOIN product AS p ON mp.product_id = p.shorten_code
WHERE g.goal_id BETWEEN #{startGoalId} AND #{endGoalId}
AND g.goal_id >= #{cursorGoalId}
ORDER BY g.goal_id
LIMIT #{limit}
결과적으로 균등한 배치시간을 확보할 수 있었습니다.