(CS) 메모리보다 큰 데이터를 정렬하는 방법(MySQL)
Database에 대해서 공부한 내용을 정리한 글입니다.
MySQL의 정렬 과정에 관한 글입니다.
실제 눈으로 보며 MySQL에서 데이터의 정렬을 효율적으로 하는 법을 공부합니다.
DB에서는 메모리보다 큰 용량을 어떻게 처리할까?
데이터를 보조 기억장치에 효율적으로 저장하는 방법으로 RDB를 정말 많이 사용합니다.
그렇다면 사실상 Backend 서버에서 항상 모든 데이터를 읽어서 서버에 적재한 뒤에 데이터를 정렬하는 방식 보다는 DB에서 처리하는게 나아보입니다.
그렇다면 DB에서는 메모리보다 큰 데이터를 정렬할때 어떤 과정을 거치는지 대표적인 RDB MySQL보며 확인해보겠습니다.
MySQL의 동작방식
MySQL도 마찬가지로 K-Way 알고리즘과 비슷한 방식의 filesort오퍼레이션이 동작합니다.
filesort 오퍼레이션은 ORDER BY절을 사용했을때 데이터가 인덱스 되지 않으면 실행됩니다.
이때 정렬은 sort_buffer에서 실행되는데 이는 세션별로 즉 커넥션별로 할당 되는 정렬을 위한 버퍼 공간입니다.
filesort 오퍼레이션 과정에서 sort_buffered_size보다 많은 양의 데이터를 메모리에 올리게 되면 임시 디스크 파일을 사용하여 merge 하는 과정을 거칩니다.
mysql 공식 문서에서는 이 과정에서 다음과 같은 최적화 방안을 제공합니다. (공식문서)
- 만약 merge 횟수가 많아질 경우에는
sort_buffered_size를 늘려 한번에 메모리에 올릴 수 있는 양을 늘립니다. read_rnd_buffered_size를 증가시켜 한번에 읽을 수 있는 row의 수를 늘립니다.
실제 sort_buffered_size보다 큰 용량의 데이터를 저장하고 정렬을 하는 과정을 직접 눈으로 보며 확인해봅시다.
실습
실습 환경
실습을 위해서 다음과 같은 테이블을 만들겠습니다.
- name에는 uuid를 할당
- score에 100,000이하의 랜덤 정수
- padding에 900byte 정도의 더미 문자열 넣기 (약 1kb로 맞춰서 계산 용이하게)
테스트 테이블 ERD
테이블 생성 SQL & 더미 데이터 삽입
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
-- 테이블 생성
CREATE TABLE user_test (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50),
score INT,
padding VARCHAR(900) -- row 크기 키우기 (1KB)
);
-- 테스트용 dummy 데이터 넣기
INSERT INTO user_test (name, score, padding)
SELECT
UUID(),
FLOOR(RAND()*100000),
RPAD('x',900,'x') -- padding 컬럼 x로 900개로 채우기
FROM
information_schema.columns a,
information_schema.columns b
LIMIT 5000000;
삽입된 데이터 예시
기본 sort_buffered_size를 확인해봅시다.
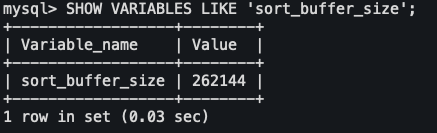
262144byte로 약 250kb 정도가 기본적으로 할당되어 있는 것을 확인할 수 있습니다.
아니 이게 말이됨?
sort buffer가 이렇게 작으면 text, blob 같 긴 데이터 1개만 들어가도 메모리에 몇개 못올리는거 아닌가?
라고 생각할 수 있는데 공식 문서에서는
1
2
3
<sort_key, rowid>
<sort_key, additional_fields>
<sort_key, packed_additional_fields>
다음과 같이 sort_key와 rowid를 key-value 형태로 조합하여 정렬한다고 합니다.
때문에 정말 큰 문자열을 기준으로 정렬하지 않는 이상, sort_key 자료형의 크기와 row_pointer의 크기가 1행을 대신하는거죠.
정렬해보자
500만 행을 모두 조회하여서 index가 없는 score를 모두 정렬하는 쿼리를 수행해보겠습니다.
데이터 모두 조회 및 정렬
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
mysql> EXPLAIN
-> SELECT *
-> FROM user_test
-> ORDER BY score DESC;
+----+-------------+-----------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| 1 | SIMPLE | user_test | NULL | ALL | NULL | NULL | NULL | NULL | 4667236 | 100.00 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+---------+----------+----------------+
-- 정렬전 상태
mysql> SHOW STATUS LIKE 'Sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 0 |
| Sort_range | 0 |
| Sort_rows | 13 |
| Sort_scan | 3 |
+-------------------+-------+
4 rows in set (0.01 sec)
mysql> EXPLAIN ANALYZE SELECT * FROM user_test ORDER BY score DESC;
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Sort: user_test.score DESC (cost=789691 rows=4.67e+6) (actual time=93654..99341 rows=5e+6 loops=1)
-> Table scan on user_test (cost=789691 rows=4.67e+6) (actual time=0.698..9332 rows=5e+6 loops=1)
|
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (1 min 40.05 sec)
-- 정렬 후 상태
mysql> SHOW STATUS LIKE 'Sort%';
+-------------------+---------+
| Variable_name | Value |
+-------------------+---------+
| Sort_merge_passes | 3121 |
| Sort_range | 0 |
| Sort_rows | 5000013 |
| Sort_scan | 4 |
+-------------------+---------+
4 rows in set (0.01 sec)
Explain의 실행 계획을 보면 Extra 부분에 Using filesort를 활용하여 별도로 정렬을 수행하는 것을 알 수 있습니다.
전체적인 실행은 다음과 같습니다.
Table scan on user_test : 전체 테이블을 스캔 (약 23초)
Sort 읽어온 모든 row를 전부 정렬 이때 임시
STATUS를 보면 500만 row를 대상으로 모두 정렬을 수행하였고 3121번의 merge가 발생했습니다.
이는 filesort를 수행할때 sort buffer의 용량이 부족하여 임시파일을 사용해 external merge sort를 수행했음을 알 수 있습니다.
정렬을 수행하면서 file 읽기 쓰기도 굉장히 많이 발생했음을 알 수 있습니다.
500만개 중에 상위 1000개만 정렬하면..?
모든 데이터를 정렬하여 가져오는 경우는 흔한 요구사항은 아닐것입니다.
특히 인덱싱되지 않은 데이터를 전체 정렬하는 상황은 드뭅니다.
하지만 많은 데이터 중 특정 컬럼의 상위 값을 정렬하여 사용자에게 보여주는 상황은 자주 발생할만한 시나리오 입니다.
인기있는 상품, 높은 조회수를 기록하고 있는 게시물 등 활용성이 높아 보입니다.
전체가 아닌 상위 N개만 필요한 경우 그 크기만큼만 정렬하면 되니 시간이 크게 줄 수 있을 거 같습니다.
상위 1000개만 정렬하여 조회하는 쿼리
###
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
mysql> EXPLAIN ANALYZE
-> SELECT *
-> FROM user_test
-> ORDER BY score DESC
-> LIMIT 1000;
+---------------------------------------------------------------------------------------------------------------------------
| EXPLAIN
| -> Limit: 1000 row(s) (cost=792450 rows=1000) (actual time=83279..83280 rows=1000 loops=1)
| -> Sort: user_test.score DESC, limit input to 1000 row(s) per chunk (cost=792450 rows=4.67e+6) (actual time=83279..83279 rows=1000 loops=1)
| -> Table scan on user_test (cost=792450 rows=4.67e+6) (actual time=7.88..18508 rows=5e+6 loops=1)
----------------------------------------------------------------------------------------------------------------------------
1 row in set (1 min 23.33 sec)
--정렬 후 상태
mysql> SHOW STATUS LIKE 'Sort%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Sort_merge_passes | 3121 |
| Sort_range | 0 |
| Sort_rows | 1007 |
| Sort_scan | 3 |
+-------------------+-------+
4 rows in set (0.01 sec)
LIMIT 1000을 걸고 같은 쿼리를 수행한 결과입니다.
위에서 모든 데이터를 대상으로 실행한 결과와 한번 비교해보겠습니다.
정렬된 rows는 당연하게도 1000개로 줄었습니다. 알고리즘의 실행시간이 굉장히 줄었을 것이라고 생각해볼 수 있습니다.
하지만 모든 row를 탐색했기 때문에 merge는 똑같이 일어나고 I/O 작업도 동일하게 발생했음을 알 수 있습니다.
시간도 드라마틱한 차이는 없습니다. 17초정도 줄었습니다. 줄어든 연산량에 비해서는 적은 차이라고 생각됩니다.
그렇다면 알고리즘 연산은 굉장히 많이 줄었지만 결국 filesort를 진행하면서 I/O 작업이 많은 시간을 차지한다는 것을 알 수 있습니다.
공식 문서에서도 정렬 시간이 길고, merge 양이 많을때 sort_buffered_size를 조정하는 방향을 가이드합니다.
공간 늘려보자!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
-- 512kb
mysql> SET SESSION sort_buffer_size = 512*1024;
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN ANALYZE
-> SELECT *
-> FROM user_test
-> ORDER BY score DESC;
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Sort: user_test.score DESC (cost=798031 rows=4.67e+6) (actual time=64879..68758 rows=5e+6 loops=1)
-> Table scan on user_test (cost=798031 rows=4.67e+6) (actual time=0.229..8038 rows=5e+6 loops=1)
|
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (1 min 9.34 sec)
-- 8MB
mysql> EXPLAIN ANALYZE
-> SELECT *
-> FROM user_test
-> ORDER BY score DESC;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Sort: user_test.score DESC (cost=800548 rows=4.67e+6) (actual time=49422..53915 rows=5e+6 loops=1)
-> Table scan on user_test (cost=800548 rows=4.67e+6) (actual time=3.01..8136 rows=5e+6 loops=1)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (54.46 sec)
mysql> SHOW STATUS LIKE 'Sort%';
+-------------------+---------+
| Variable_name | Value |
+-------------------+---------+
| Sort_merge_passes | 96 |
| Sort_range | 0 |
| Sort_rows | 5000007 |
| Sort_scan | 3 |
+-------------------+---------+
4 rows in set (0.02 sec)
Buffer 용량을 늘릴수록 시간이 점차 감소한 것을 볼 수 있습니다.
| 시간 | merge | |
|---|---|---|
| 256kb | 1m 40.05sec | 3121 |
| 512kb | 1m 9.34sec | 1596 |
| 8MB | 54.46sec | 96 |
결국 filesort의 중요한 포인트는 I/O 시간임을 알 수 있습니다.
하지만 sort_buffer_size를 무한정으로 늘리면 발생할 수 있는 문제들이 있습니다.
위에서 언급했듯 sort buffer는 세션별로 할당됩니다.
사실상 connection_size * sort_buffered_size는 굉장히 많은 메모리를 차지할 수 있습니다.
만약 write가 아닌 read가 훨씬 더 자주 발생하는 환경이라면, 굳이 filesort를 내버려두지 않고 covering index를 사용하면 지금까지 고민이 무색 할 정도로 빠른시간내 탐색이 가능하다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
mysql> CREATE INDEX idx_score_id
-> ON user_test(score DESC, id);
Query OK, 0 rows affected (9.66 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN ANALYZE
-> SELECT *
-> FROM user_test
-> ORDER BY score DESC LIMIT 10000;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Limit: 10000 row(s) (cost=703 rows=10000) (actual time=4.97..355 rows=10000 loops=1)
-> Index scan on user_test using idx_score_id (cost=703 rows=10000) (actual time=4.96..354 rows=10000 loops=1)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.36 sec)
360ms ㅎㄷㄷ..
알게된 점
- 대규모 데이터를 대량으로 정렬해서 가져와야 하는 환경이라면, order by절을 잘 확인하고 indexing하자.
- 같은 테이블에 보조 인덱스가 많이 걸려있는 상황이라면, buffer size를 조절해보는 노력을 해보자
- 이 마저도 리소스가 안된다면 아키텍처로 풀어야한다. (캐싱, 파티셔닝 등)
- filesort의 시간 비용은 알고리즘보다는 I/O의 문제일 수 있다.
Order By가 I/O를 점유해서 다른 유저들의 속도가 느려지는 시나리오..