(Cache) 캐시 제거 알고리즘과 장애 패턴들
캐시 제거 알고리즘과 장애 패턴들
Backend에서 캐시를 운영할 때 자주 마주치는 이슈를 정리한 글입니다.
Cache eviction 알고리즘과 장애 패턴 중심으로 정리해봅니다.
Study 동기
캐시는 보조기억장치에 데이터를 미리 주기억장치에 저장하여 빠르게 데이터에 접근하게 해줍니다. 이를 통해서 대규모 환경에서 부하를 줄이거나 트래픽이 몰릴때 시스템이 버티게 해줍니다.
하지만 메모리(RAM)은 대부분 보조기억장치보다 크기가 작고 제한된 리소스를 갖고 있습니다.
때문에 캐시에서는 메모리가 차게되면
- 어떤 데이터를 버릴지
- 이 데이터를 언제 만료할지
- 장애 패턴이 왔을 때 어떤 순서로 막을지
이런 대응 전략이 필요합니다. 캐시를 적용하는 것도 좋지만 실제 운영 환경에서 어떤 전략을 취해야할지 궁금해졌고 스터디해보았습니다.
1. Cache Eviction
Cache Eviction 이란?
Cache eviction은 메모리가 한정되어 있을 때, 어떤 데이터를 캐시에서 제거할지 결정하는 정책입니다.
메모리는 무한하지 않기 때문에 결국 “새 데이터를 넣기 위해 기존 데이터를 버리는 기준”이 필요합니다.
대표 알고리즘
LRU (Least Recently Used)
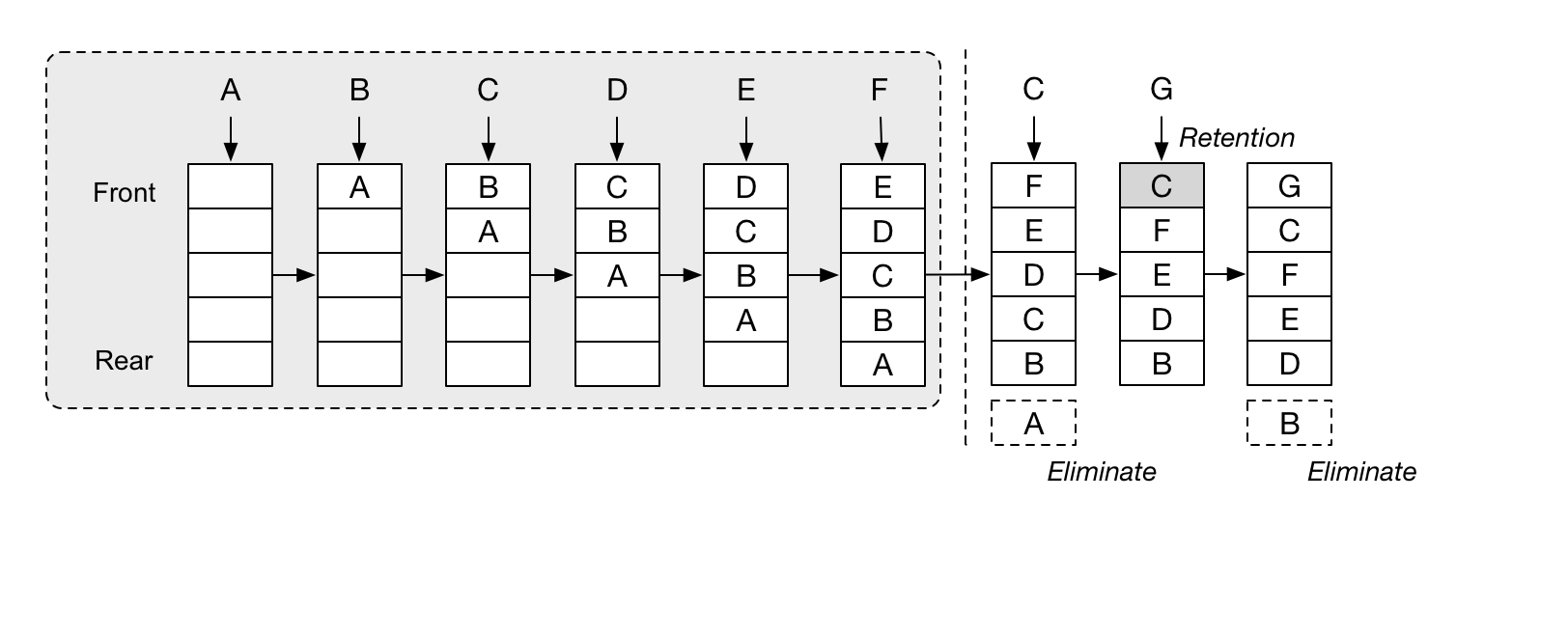 가장 오랫동안 접근되지 않은 키를 제거합니다. 최근 접근 이력을 중요하게 보는 정책입니다.
가장 오랫동안 접근되지 않은 키를 제거합니다. 최근 접근 이력을 중요하게 보는 정책입니다.
원리는 단순합니다.
- key를 조회하거나 갱신할 때마다 “최근에 사용됨” 상태로 맨 앞으로 보냅니다.
- eviction이 필요해지면 가장 뒤에 있는, 즉 가장 오래 접근되지 않은 key를 제거합니다.
보통 hash + doubly linked list 구조로 구현합니다. hash는 key를 O(1)에 찾기 위해 필요하고, linked list는 접근된 key를 앞쪽으로 옮기고 가장 오래된 key를 뒤에서 제거하기 위해 필요합니다.
언제 잘 맞을까?
- 사용자의 최근 조회 내역처럼 “방금 본 데이터를 다시 볼 가능성”이 높은 경우
- 일반적인 조회 API처럼 트래픽의 지역성(locality)이 강한 경우
세션성 데이터, 최근 조회 목록, 짧은 시간 동안 반복 조회되는 객체 캐시에 적합
- 장점: 지역성(locality)이 있는 일반적인 API 트래픽에서 안정적
- 단점: 과거에 자주 쓰였지만 앞으로 중요한 키를 놓칠 수 있음
LFU (Least Frequently Used)
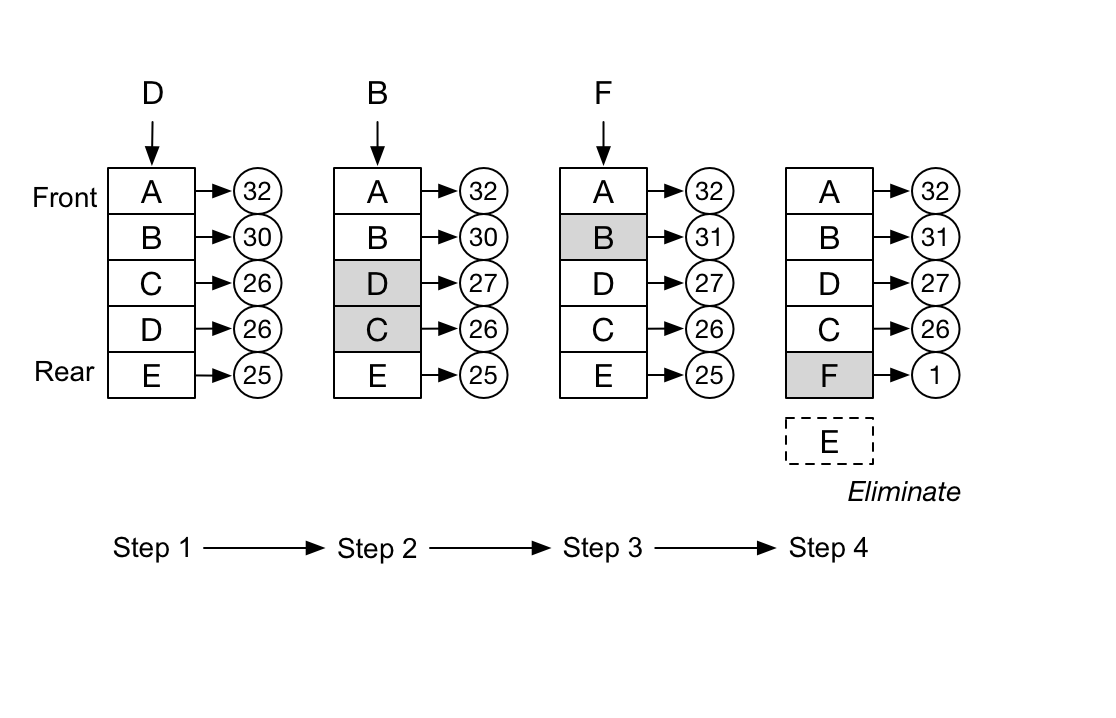 접근 빈도가 가장 적은 키를 제거합니다. “얼마나 자주 쓰였는지”를 핵심 기준으로 봅니다.
접근 빈도가 가장 적은 키를 제거합니다. “얼마나 자주 쓰였는지”를 핵심 기준으로 봅니다.
이 알고리즘은 key마다 접근 횟수를 기록해두고, eviction 시점에 가장 적게 사용된 key를 제거합니다.
즉 LRU가 “최근에 썼는가”를 보는 정책이라면, LFU는 “전체적으로 많이 쓰였는가”를 보는 정책입니다.
구현은 보통 key별 frequency counter와 frequency bucket을 함께 둡니다. 그래야 조회가 일어났을 때 count를 증가시키고, 해당 key를 다음 frequency bucket으로 옮길 수 있습니다.
언제 잘 맞을까?
- 소수의 hot key가 장기간 반복적으로 조회되는 경우
- 인기 게시물, 인기 상품, 랭킹 정보처럼 특정 데이터 쏠림이 강한 경우
- “최근성”보다 “누적 인기”가 더 중요한 읽기 패턴에서 유리
다만 단점도 분명합니다. 한 번 많이 조회된 key가 오래 남기 쉬워서, 트래픽 패턴이 빠르게 바뀌는 시스템에서는 오히려 stale한 key가 버티는 문제가 생길 수 있습니다.
- 장점: 핫키가 오래 유지되기 쉬움
- 단점: 초기 학습 구간에서 오판 가능, 카운터 관리 비용 필요
FIFO (First In First Out)
먼저 들어온 키부터 제거합니다. 구현이 단순합니다.
원리는 queue와 거의 같습니다. 먼저 들어온 데이터를 먼저 내보냅니다.
중요한 점은 이 정책은 “최근에 다시 조회되었는지”, “얼마나 많이 조회되었는지”를 전혀 보지 않는다는 것입니다. 오직 들어온 순서만 기준으로 삼습니다.
언제 잘 맞을까?
- 캐시 품질보다 구현 단순성과 예측 가능한 동작이 중요한 경우
- 데이터 재사용성보다는 임시 버퍼 역할에 가까운 경우
접근 패턴이 복잡하지 않고, 캐시 miss 비용이 비교적 작을 때
- 장점: 구현 단순, 예측 가능
- 단점: 최근/빈도 정보 반영 못함
Random
무작위로 제거합니다.
이름 그대로 eviction 대상이 필요할 때 랜덤하게 victim key를 고릅니다.
겉으로 보면 굉장히 단순하고 무식해 보이지만, 관리 비용이 작고 특정 패턴에 편향되지 않는다는 장점이 있습니다. 즉 “어떤 메타데이터도 유지하지 않겠다”는 선택에 가깝습니다.
언제 잘 맞을까?
- 캐시 메타데이터 관리 비용을 극단적으로 줄이고 싶은 경우
- 키 수가 매우 많고, 접근 패턴 예측보다 단순 운영이 중요한 경우
캐시가 보조적인 최적화 수단일 뿐, miss가 치명적이지 않을 때
- 장점: 구현/오버헤드가 작음
- 단점: 중요한 키가 제거될 수 있어 히트율 예측이 어려움
TTL 기반 제거
TTL(Time To Live)이 지난 키를 만료로 제거합니다. 엄밀히는 evict 정책이라기보다 만료 정책에 가깝지만, 실제 운영에서는 eviction과 함께 동작합니다.
이 정책은 “얼마나 자주 쓰였는가”보다 “이 데이터가 언제까지 유효한가”를 기준으로 둡니다.
예를 들어 10초 TTL을 둔 key는 10초가 지나면 캐시 hit 대상에서 제외됩니다. 이후 접근이 들어오면 다시 원본 저장소에서 읽어와 캐시를 채웁니다.
언제 잘 맞을까?
- 데이터의 신선도가 중요한 경우
- 외부 API 응답, 인증/인가 정보, 통계 집계값처럼 유효기간이 명확한 경우
- 캐시 정합성을 완화하되, 오래된 데이터가 무한히 남는 것은 막고 싶은 경우
실무에서는 TTL만 단독으로 쓰기보다 LRU/LFU + TTL을 같이 둡니다. 왜냐하면 TTL은 유효기간을 관리하고, LRU/LFU는 메모리 압박 상황에서 무엇을 먼저 버릴지 관리하기 때문입니다.
- 장점: 데이터 신선도 제어 가능
- 단점: TTL 설계를 잘못하면 동시 만료 문제(avalanche) 유발
시간복잡도
| 알고리즘 | 조회/갱신 | 제거 대상 선택 | 비고 |
|---|---|---|---|
| LRU | O(1) | O(1) | hash + doubly linked list |
| LFU | O(1) (평균) | O(1) (평균) | freq bucket 구조 가정 |
| FIFO | O(1) | O(1) | queue 구조 |
| Random | O(1) | O(1) | 랜덤 샘플링 |
| TTL | O(1)~O(logN) | O(1)~O(logN) | 만료 큐/샘플링 전략에 따라 달라짐 |
어느 캐시 서비스를 쓰냐에 따라서 구현체가 달라지기 때문에 항상 위와 같지 않습니다.
언제 어떤 정책을 쓰는가?
- LRU: 일반적인 조회 API, 최근성 기반 트래픽
- LFU: 조회 편향이 강한 서비스(핫키가 뚜렷함)
- FIFO/Random: 단순 캐시 계층, 비용 최소화가 우선인 경우
- TTL: 정합성/신선도 요구가 있는 도메인에서 필수
실무에서는 보통 LRU or LFU + TTL 조합으로 갑니다.
조금 더 현실적으로 정리하면 다음과 같습니다.
- 최근에 본 데이터를 다시 볼 가능성이 높다 -> LRU
- 소수의 인기 key가 계속 살아남아야 한다 -> LFU
- 캐시 품질보다 단순한 운영이 더 중요하다 -> FIFO or Random
- 데이터가 오래되면 안 된다 -> TTL은 거의 필수
결국 선택 기준은 알고리즘 이름이 아니라 트래픽 패턴입니다. 캐시 정책은 “좋은 알고리즘 고르기” 문제가 아니라 “우리 서비스 접근 패턴에 맞는 기준을 고르기” 문제에 가깝습니다.
Redis의 eviction 정책
Redis maxmemory-policy 기준으로 자주 쓰는 정책은 다음과 같습니다. 공식문서
noeviction: 메모리 한도 도달 시 쓰기 에러allkeys-lru: 전체 키 대상 LRU 기반 제거volatile-lru: expire 설정된 키 대상 LRU 제거allkeys-lfu: 전체 키 대상 LFU 기반 제거volatile-lfu: expire 설정 키 대상 LFU 제거allkeys-random: 전체 키 대상 랜덤 제거volatile-random: expire 설정 키 대상 랜덤 제거volatile-ttl: expire 키 중 TTL이 짧은 키 우선 제거
Redis는 내부적으로 근사(approximation) 전략을 사용해 비용과 성능을 균형 맞춥니다. 그래서 “이론 100% LRU/LFU”라기보다는 “운영 친화적인 근사 LRU/LFU”에 가깝습니다.
2. 캐시 장애 패턴들
캐시 장애는 대부분 공통적으로 Miss 폭증 -> DB 부하 상승 -> 지연/타임아웃 경로를 탑니다. 패턴만 잘 알아도 대응 순서가 빨라집니다.
2-1. Cache Stampede (동시 다발적 캐시 미스)
동일 키가 만료되는 순간, 다수 요청이 동시에 원본(DB)으로 몰리는 현상입니다.
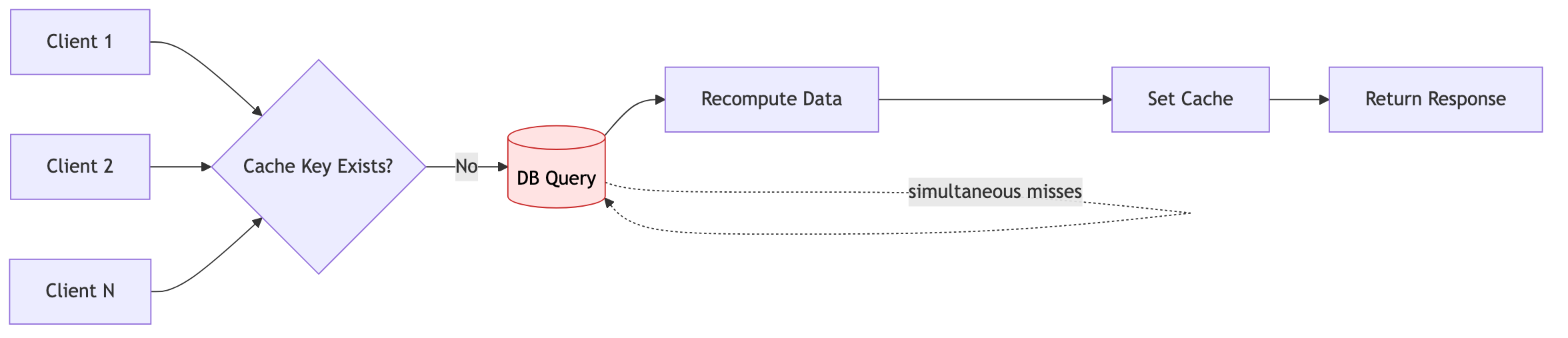
해결 방안:
- Single Flight (동일 키 재계산 1회로 제한): 같은 key에 대한 중복 재계산을 막아 DB로 동시에 내려가는 요청 수를 줄입니다.
- Mutex/분산락으로 재생성 직렬화: 한 요청만 원본 데이터를 다시 읽게 하고 나머지는 기다리게 만들어 stampede를 완화합니다.
- Soft TTL + 백그라운드 리프레시: 사용자 요청 경로에서 즉시 만료시키지 않고, 뒤에서 미리 갱신해 순간적인 miss 폭증을 줄입니다.
- 짧은 랜덤 지연(jitter): 동일 시점에 재시도하거나 재생성하는 요청 타이밍을 분산시켜 부하 집중을 완화합니다.
2-2. Cache Avalanche (연쇄적 대량 만료)
많은 키의 TTL이 비슷해서 같은 시점에 대량 만료되는 현상입니다.
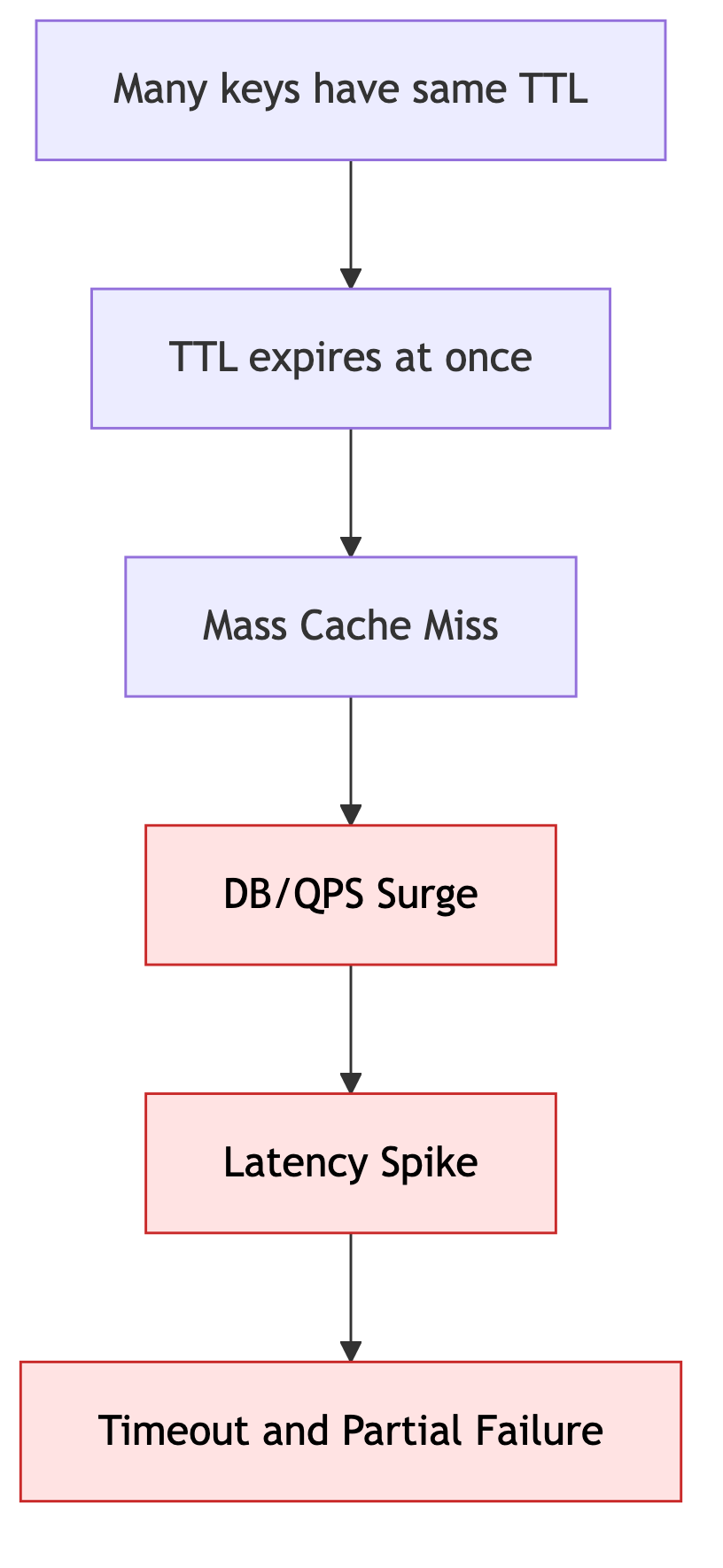
해결 방안:
- TTL에 랜덤값 추가 (
base + jitter): 같은 시간에 key가 한꺼번에 죽지 않도록 만료 시점을 흩뜨립니다. - 계층 캐시(L1/L2) 구성: 1차 캐시 miss가 나더라도 2차 캐시가 완충 역할을 하도록 만들어 원본 부하를 줄입니다.
- 만료 분산 배치: 대량 key를 같은 시점에 적재하거나 갱신하지 않게 해서 avalanche 조건 자체를 줄입니다.
- Rate Limit / Circuit Breaker 적용: 이미 miss가 폭증한 상황에서 backend가 같이 무너지지 않도록 요청량을 제한합니다.
2-3. Cache Breakdown (핫키 장애)
핫키 하나가 만료되며 해당 키에 트래픽이 집중되어 백엔드가 터지는 패턴입니다.
여기서 hot key라는 것은 유난히 많은 요청이 몰리는 특정 key를 의미합니다. 예를 들어 인기 게시물, 실시간 랭킹, 메인 화면 공통 데이터처럼 모두가 반복해서 조회하는 key가 대표적입니다.

해결 방안:
- 핫키는 만료 제거 대신 수동 갱신(또는 긴 TTL): 가장 위험한 key가 갑자기 사라지는 상황 자체를 줄입니다.
- 핫키 사전 워밍(warm-up): 트래픽이 몰리기 전에 캐시에 미리 올려 breakdown 가능성을 낮춥니다.
- 요청 병합(Request Coalescing): 동일 key에 대한 다수 요청을 하나의 원본 조회로 합쳐 backend 부하를 줄입니다.
- 장애 시 stale 데이터 임시 허용: 잠시 오래된 데이터를 반환하더라도 원본 시스템이 죽는 상황을 피하는 것이 목적입니다.
2-4. Cache Thrashing (과도한 캐시 교체)
작업 집합(working set)이 캐시 용량보다 커서 넣고 지우기를 반복하며 히트율이 급락하는 현상입니다.

해결 방안:
- 캐시 용량 증설 or 샤딩 재조정: working set이 실제로 캐시에 들어갈 수 있게 만들어 불필요한 축출 반복을 줄입니다.
- 키/값 크기 축소: 같은 메모리 안에 더 많은 유효 데이터를 담을 수 있게 하여 thrashing을 완화합니다.
- 캐시 대상 재선정 (모든 데이터 캐시 금지): 재사용성이 낮은 데이터까지 넣지 않도록 해서 중요한 key가 더 오래 남게 합니다.
- LFU 전환 검토 (핫키 유지력 향상): 자주 쓰는 key를 더 오래 유지하도록 만들어 hit ratio를 개선할 수 있습니다.
2-5. Eviction Failure Pattern (잘못된 축출로 인한 장애)
메모리 압박에서 eviction이 과도하게 일어나 중요한 키가 밀리며 miss가 연쇄적으로 발생하는 패턴입니다.
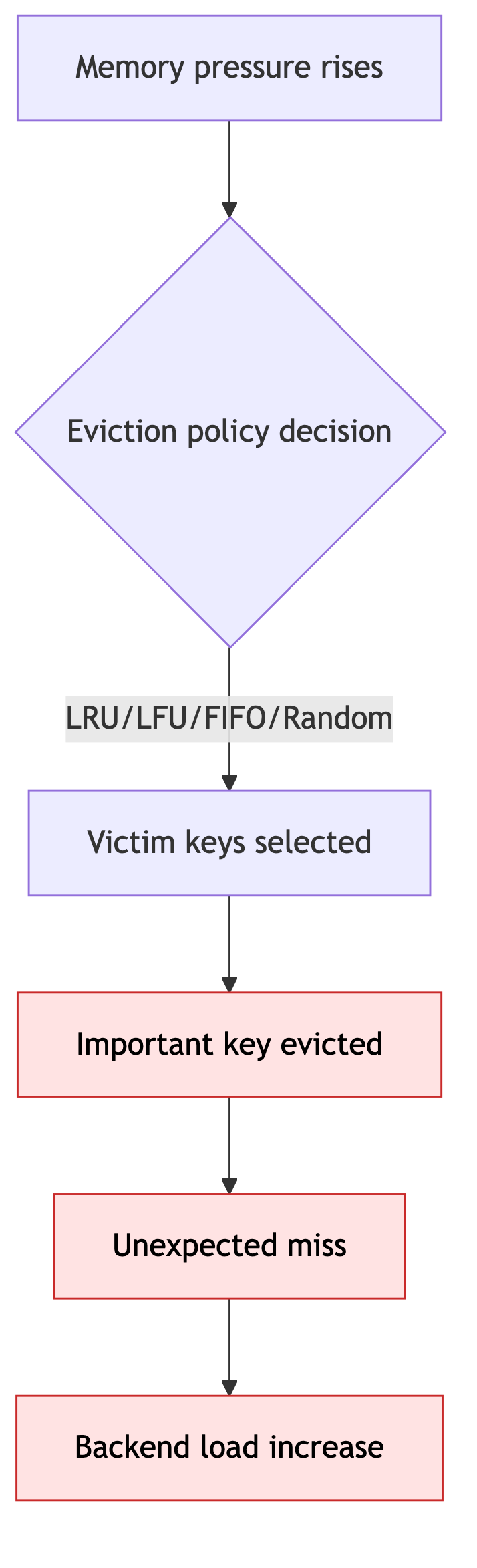
해결 방안:
- 정책 재검토 (
allkeys-lruvsallkeys-lfu등): 현재 접근 패턴에 맞지 않는 eviction 정책이면 중요한 key가 과도하게 밀릴 수 있습니다. maxmemory와 객체 크기 분포 재측정: 메모리 한도와 객체 크기 편향을 같이 봐야 어떤 key가 왜 밀리는지 판단할 수 있습니다.- 큰 키(big key) 분해: 일부 큰 key가 메모리를 과도하게 점유하면 eviction 압력이 급격히 커지기 때문에 이를 줄여야 합니다.
- 키별 중요도에 따른 TTL/namespace 분리: 모든 key를 같은 기준으로 다루지 않고, 중요한 데이터가 먼저 밀리지 않도록 정책을 분리합니다.
정리
캐시 전략의 핵심은 “어떻게 넣을까” 보다 “언제, 무엇을 버릴까”에 가깝습니다.
그리고 실제 장애는 대부분 알고리즘 자체보다 운영 설정(TTL, 용량, 핫키 관리)에서 시작됩니다.
결국 캐시는 자료구조 문제가 아니라 운영 설계 문제라는 걸 계속 느끼게 됩니다.