(MagicOfConch) FCM 알림 배치 100만건 최적화기 - 1
MagicOfConch(마법의 소라고동) 프로젝트의 Streak 알림 배치를 단계적으로 개선한 기록입니다. Stack: Spring Batch, JPA, RabbitMQ, Prometheus, Grafana 1분에 100만 명에게 알림을 보내야 한다면 이 배치는 살아남을 수 있을까? 라는 질문에서 시작합니다.
어떤 기능인가?
마법의 소라고동은 “회고 습관 형성 서비스”인 만큼 사용자가 설정한 시간에 회고 작성을 유도하는 Push 알림을 전송하는 기능이 필요합니다.
만약 사용자가 20:20에 회고 작성을 하고자 시간을 설정했다면 해당 시간(20:20)에 적정 멘트로 사용자에게 알림이 전송되어야합니다.
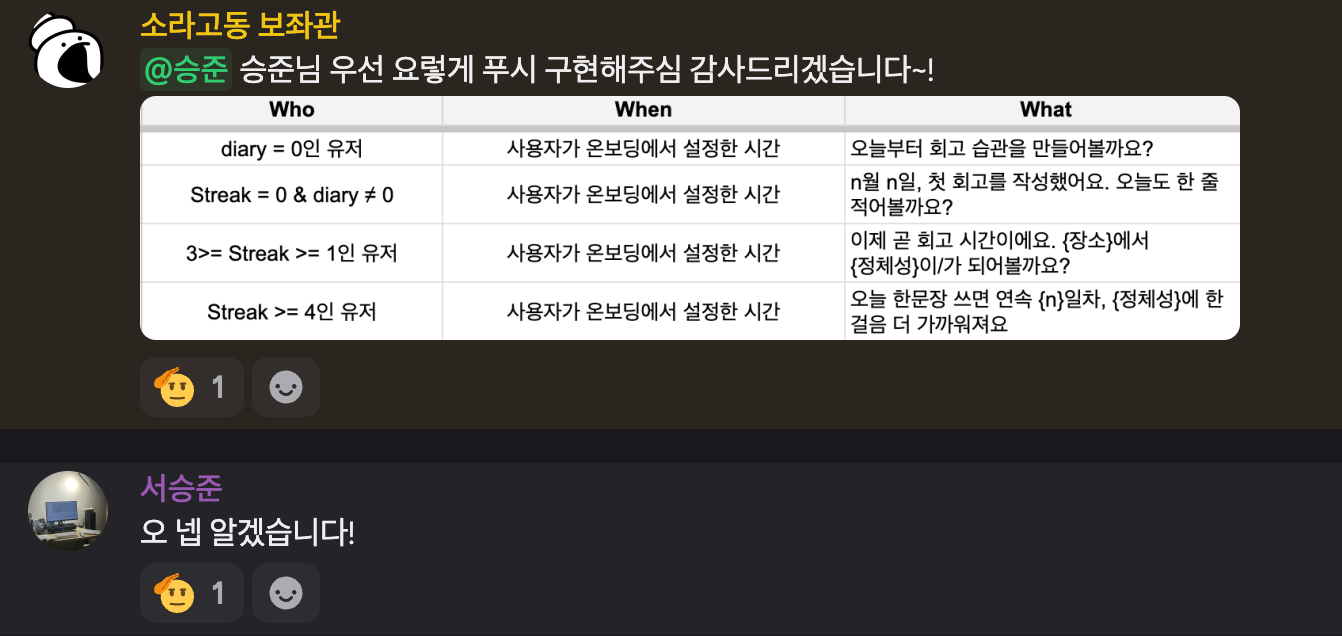
기획자분에게 알림 멘트관련 요구사항을 다음과 같이 전달받았습니다.
이 기능을 Spring Batch로 구현했습니다. 배치 Job이 1분 단위로 실행되면서, 해당 분에 알람이 설정된 사용자만 골라서 FCM 메시지를 만든 후 발송합니다.
처음 개발할 때는 사용자가 많지 않았기 때문에 단순한 구조로 빠르게 만들었습니다.
서비스 특성상 회고 작성시간을 저녁으로 설정하는 유저가 대부분이었고, 이렇게 특정 시간에 알림을 보내야할 사용자가 다량 누적되었을때 제 시간에 사용자에게 알림이 전달될 수 있을지 고민하게되었습니다.
이를 위해서 더 높은 가용성의 배치시스템의 필요성을 느꼈고 만약 사용자가 100만 명이 넘는 시점이 오면 이 배치가 견딜 수 있을지 궁금했습니다.
직접 100만 건의 더미 데이터를 넣고 직접 현재 서버에서 감당 가능할지 확인해봤습니다.
서버 환경
현재 서비스는 집에 있는 미니 PC에서 서버를 온프레미스로 운영중이고 Docker로 환경을 구성했습니다.
| 항목 | 모델명 | 사양 |
|---|---|---|
| CPU | N100 CPU | 4C/4T |
| RAM | 미니PC 내장 RAM | 16GB |
| SSD | 삼성전자 860 EVO mSATA | 512GB |
목데이터 구성
- 100만 명의 user (유저 정보)
- 100만 개의 streak_info(회고 습관 메타데이터)
- 약 1250만 개의 review(회고)로 구성했습니다.
- 사용자당 0~50개의 review를 랜덤하게 분포시켰고,
streak_info.review_at은 70%를 저녁 시간대(18~22시)에 몰아 두었습니다. - 또한
22:00에는 100만 사용자 목데이터를 만들어 대규모 처리를 테스트 했습니다.
- 사용자당 0~50개의 review를 랜덤하게 분포시켰고,
1. 기존 구현 - JpaCursorItemReader
과거에 MyBatis기반의 Cursor 기반의 페이지네이션으로 배치 처리를 진행하나 경험이 있어서 대규모 처리에 적합하다고 생각하여 JPA에서 지원하는 JpaCursorItemReader 를 사용했습니다.
처음 작성한 Reader는 다음과 같습니다.
사용자의 얻을 수 있는
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Bean
@StepScope
public JpaCursorItemReader<UserInfo> streakReader(
EntityManagerFactory entityManagerFactory,
@Value("#{jobExecutionContext['alertTime']}") LocalDateTime alertTime) {
return new JpaCursorItemReaderBuilder<UserInfo>()
.name("streakUserInfoReader")
.entityManagerFactory(entityManagerFactory)
.queryString("SELECT u FROM UserInfo u "
+ "LEFT JOIN FETCH u.osAuthInfo oi "
+ "LEFT JOIN FETCH u.streakInfo si "
+ "WHERE FUNCTION('HOUR', si.reviewAt) = :hour "
+ "AND FUNCTION('MINUTE', si.reviewAt) = :minute "
+ "ORDER BY u.id")
.build();
}
UserInfo와 연관 엔티티를 한 번에 가져오고, Processor에서 메시지를 분기, Writer에서 FCM을 발송합니다. 단순한 chunk 기반 배치입니다.
이 상태에서 19시 15분에 4만 5천여 명을 대상으로 돌렸을 때 결과는 다음과 같습니다.
1
Job: [streakAlertJob] completed in 1m6s716ms
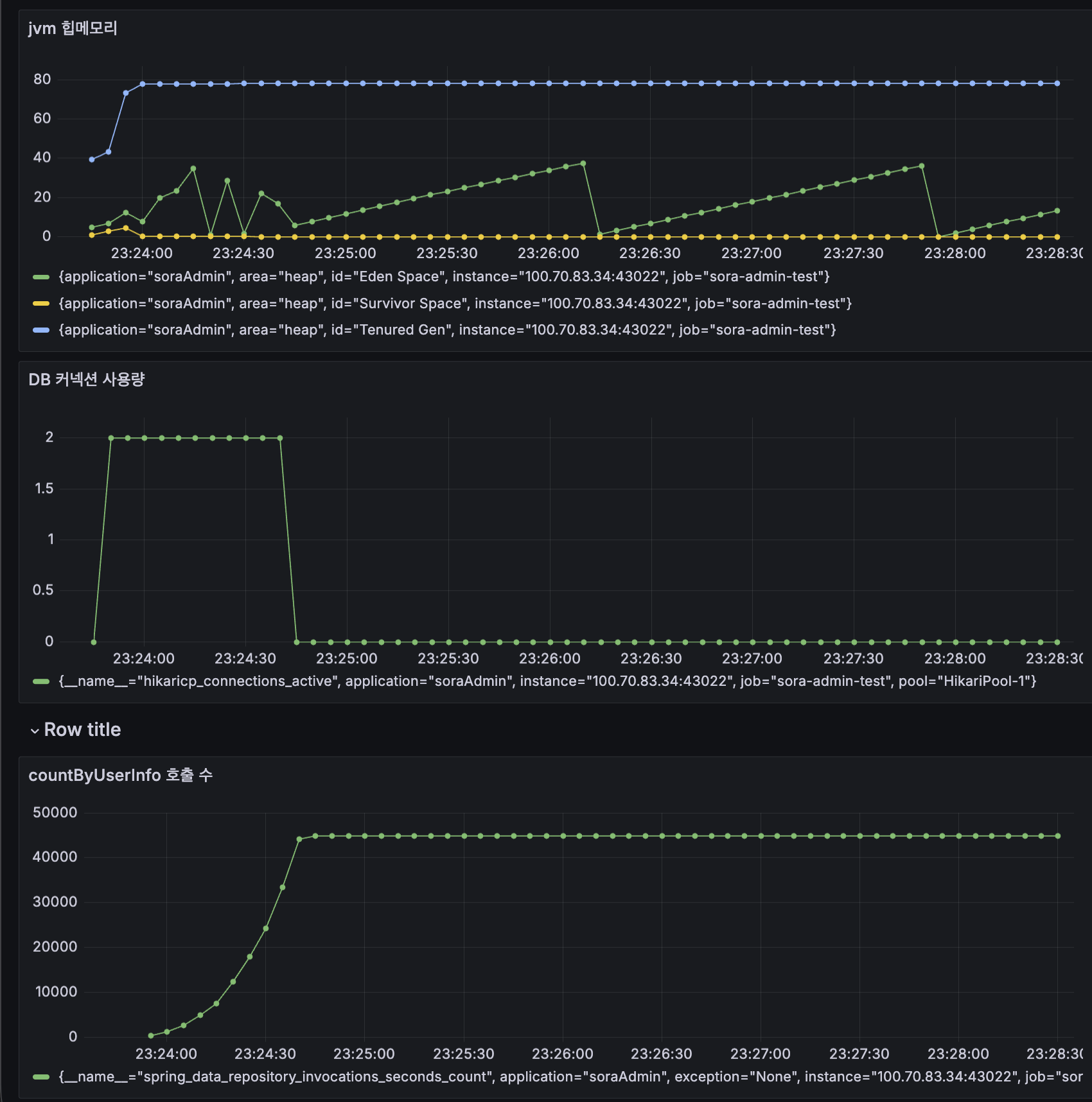
44,945건에 약 1분 7초정도 걸렸습니다. 아마 100만명의 유저를 대상으로 수행한다면 20배 넘는 시간이 걸릴것입니다.
2. Processor의 DB 조회 제거
Hibernate statistics를 켜두고 프로메테우스의 메트릭에서 발견한 JPA 메서드 호출입니다.
1
2
spring_data_repository_invocations_seconds_count{method="countByUserInfo"} = 44,945
spring_data_repository_invocations_seconds_sum = 35.01초
countByUserInfo가 44,945번 호출되고, 그 호출이 차지한 누적 시간이 35초 였습니다. 전체 배치 시간 1분 6초 중 67%가 이 메서드 호출이었습니다.
원인은 Processor 코드였습니다. 기존 Processor의 주요 역할은 위 요구사항에 맞게 유저별로 알림 멘트를 분류하는 역할이었습니다.
사용자의 review(회고) 작성 개수의 비교를 위해서 Processor 루프 안에서 명시적으로 count 쿼리를 발생시키는 구조입니다.
1
2
3
4
5
6
7
8
// 회고 횟수 분기를 위해서 유저당 1번씩 count 쿼리 발생
int count = reviewRepository.countByUserInfo(userInfo);
if (count <= 0) {
body = zeroReview;
} else if (streakInfo.getReviewStreakCount() == 0) {
body = String.format(streakZeroReviewNonZero, ...);
} ...
추가적인 쿼리를 줄인다면, 시간 단축을 기대할 수 있을거라 생각했습니다. DB를 찌르는 횟수가 2배로 주니까요
또한 Spring Batch 아키텍처에서 Processor에서 DB에서 값을 읽어 오는 것은 권장되지 않느다고 합니다.
그 대안으로 서브쿼리를 사용하는 것은 어떤지 하는 스택오버 플로우 글을 보게되었고 현 상황에 도입해볼 수 있다고 생각했습니다.
왜 Processor에서 DB를 찌르면 안 되는가?
Spring Batch의 Reader-Processor-Writer 모델에서 I/O는 Reader와 Writer가 맡고, Processor는 CPU 변환(필터링·분기·매핑)만 담당하는 것이 모범 패턴입니다.
Processor에서 item마다 DB 조회를 하면 호출 횟수가 item 수에 선형 비례합니다.
chunk size만큼 모아서 처리할 수 있는 Reader/Writer와 달리, Processor는 item 1건당 1번 실행되기 때문에 per-item query의 비용이 그대로 N배로 누적됩니다.
1
2
3
4
5
6
7
8
9
.queryString("SELECT u, "
+ "(SELECT MIN(r.reviewDate) FROM Review r WHERE r.userInfo = u), "
+ "(SELECT COUNT(r) FROM Review r WHERE r.userInfo = u) "
+ "FROM UserInfo u "
+ "LEFT JOIN FETCH u.osAuthInfo oi "
+ "LEFT JOIN FETCH u.streakInfo si "
+ "WHERE si.reviewAt >= :start "
+ "AND si.reviewAt < :end "
+ "ORDER BY u.id")
JPA에서 SELECT u, ... 처럼 여러 컬럼을 조회하면 Object[]로 결과가 반환되기 때문에, Reader에서 이를 받아 DTO로 매핑해줬습니다.
개선한 Reader 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
@Bean
@StepScope
public ItemStreamReader<UserStreakItem> streakReader(EntityManagerFactory entityManagerFactory,
@Value("#{jobExecutionContext['alertTime']}") LocalDateTime alertTime) {
JpaCursorItemReader<Object[]> delegate = new JpaCursorItemReaderBuilder<Object[]>()
.name("streakUserInfoReader")
.entityManagerFactory(entityManagerFactory)
.queryString("SELECT u, "
+ "(SELECT MIN(r.reviewDate) FROM Review r WHERE r.userInfo = u), "
+ "(SELECT COUNT(r) FROM Review r WHERE r.userInfo = u) "
+ "FROM UserInfo u "
+ "LEFT JOIN FETCH u.osAuthInfo oi "
+ "LEFT JOIN FETCH u.streakInfo si "
+ "WHERE si.reviewAt >= :start "
+ "AND si.reviewAt < :end "
+ "ORDER BY u.id")
.parameterValues(Map.of(
"start", alertTime.toLocalTime().withSecond(0).withNano(0),
"end", alertTime.toLocalTime().withSecond(0).withNano(0).plusMinutes(1)
))
.build();
try {
delegate.afterPropertiesSet();
} catch (Exception e) {
throw new ItemStreamException("Failed to initialize delegate reader", e);
}
return new ItemStreamReader<>() {
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
delegate.open(executionContext);
}
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
delegate.update(executionContext);
}
@Override
public void close() throws ItemStreamException {
delegate.close();
}
@Override
public UserStreakItem read() throws Exception {
Object[] item = delegate.read();
if (item == null)
return null;
return new UserStreakItem((UserInfo) item[0], (LocalDate) item[1], (Long) item[2]);
}
};
}
같은 4만 5천 건을 다시 돌려본 결과는 다음과 같습니다.
1
Job: [streakAlertJob] completed in 22s489ms
1분 6초 → 22초, 약 65% 단축되었습니다.
3. 진짜 부하 - 100만 건
여기까지는 베이스라인이고, 진짜 궁금한 건 100만 건이었습니다. UPDATE streak_info SET review_at = '22:00:00' 으로 모든 사용자의 알람 시간을 한 시점에 몰아넣고 다시 돌려봤습니다.
배치 결과
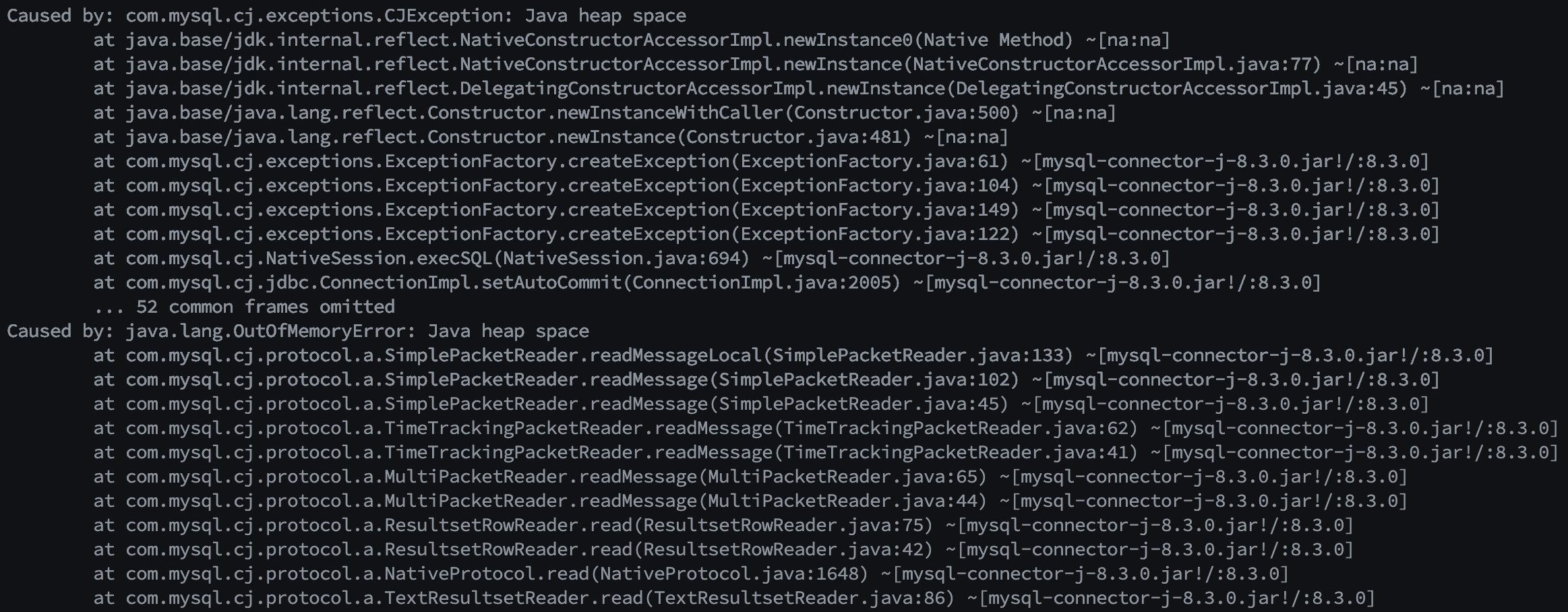
결과는 OOM(Out Of Memory) 이었습니다. Chunk 기반 Batch를 수행했고, Chunk size = 50이었기 때문에 OOM이 이해가 되지 않았습니다.
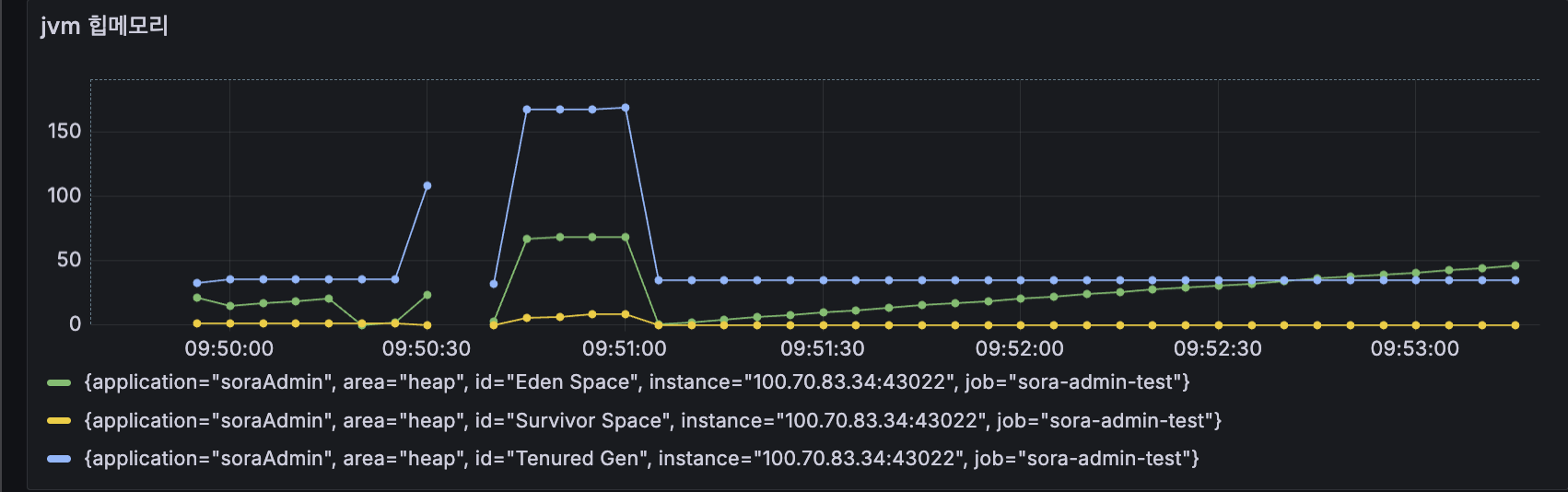
Grafana를 보니 배치가 돌아가는 내내 DB 커넥션이 반납되지 않고 계속 점유되고 있었습니다. Chunk 기반 배치인데 왜 메모리가 터질까? JpaCursorItemReader의 동작 원리를 다시 짚어볼 필요가 있었습니다.
JpaCursorItemReader 동작 원리
JpaCursorItemReader는 이름 그대로 DB의 커서를 열어두고 한 행씩 스트리밍하는 Reader입니다.
- 배치가 시작되면 EntityManager를 하나 생성합니다.
- DB에 커서를 열고 첫 번째 행부터 한 행씩 받아옵니다.
- chunk 사이즈만큼 모이면 Processor → Writer → flush + commit.
- 다시 다음 행을 받아옵니다.
- 모든 행을 다 읽을 때까지 같은 EntityManager(=같은 영속성 컨텍스트)를 유지합니다.
여기서 함정이 있습니다. Spring Batch는 chunk 끝에서 flush와 commit은 하지만 clear는 하지 않습니다.
flush vs clear vs close
flush(): 변경사항(dirty)을 DB에 반영합니다. 엔티티는 영속성 컨텍스트에 그대로 남아 있습니다.clear(): 영속성 컨텍스트에서 모든 엔티티를 detach 시킵니다. 메모리에서 GC 대상이 됩니다.close(): EntityManager 자체를 닫습니다.flush와 clear는 다릅니다. flush 만 한다고 메모리가 비워지지 않습니다.
즉 chunk마다 flush + commit이 일어나도, 읽어들인 엔티티는 계속 영속성 컨텍스트에 쌓입니다.
1
2
3
4
5
chunk 1: UserInfo 50개 누적
chunk 100: 5,000개 누적
chunk 1000: 50,000개 누적
...
chunk 20000: 1,000,000개 → OOM
연관 엔티티(StreakInfo, OsAuthInfo)까지 합치면 100만 건은 약 300만 개의 엔티티가 메모리에 상주합니다. 컨테이너 메모리 1GB 안에 들어갈 리가 없죠.
그러면 chunk 끝에 clear() 하면 되지 않나?
안 됩니다. 커서가 EntityManager에 의존하고 있기 때문입니다.
1
2
3
clear() 호출 → 영속성 컨텍스트가 비워짐
→ 커서가 참조하던 상태도 같이 사라짐
→ 다음 read() 시 NPE
이게 Cursor 방식의 구조적 딜레마입니다.
1
2
3
커서를 유지하려면 → EntityManager를 열어둬야 함
메모리를 줄이려면 → clear()로 비워야 함
→ 둘을 동시에 할 수 없음
Cursor의 한계
이번 OOM을 계기로 정리한 JpaCursorItemReader의 단점은 다음과 같습니다.
- 영속성 컨텍스트 누적으로 인한 OOM - 100만 건이면 100만 + α 개의 엔티티가 쌓입니다.
- DB 커넥션 장시간 점유 - 커서를 유지하기 위해 배치 전체 시간 동안 커넥션 1개를 잡고 있습니다. 실측으로
hikaricp_connections_usage_seconds_max = 50.4초가 찍혔습니다. - Dirty Checking 비용 증가 - flush 시 영속성 컨텍스트의 모든 엔티티를 검사합니다. 뒤로 갈수록 검사 대상이 많아져서 느려집니다.
- Partition 확장 불가 - 여러 스레드가 각자 커서를 들고 있으면 커넥션이 그만큼 잡힙니다. HikariCP가 빠르게 고갈됩니다.
JpaCursorItemReader의 동작
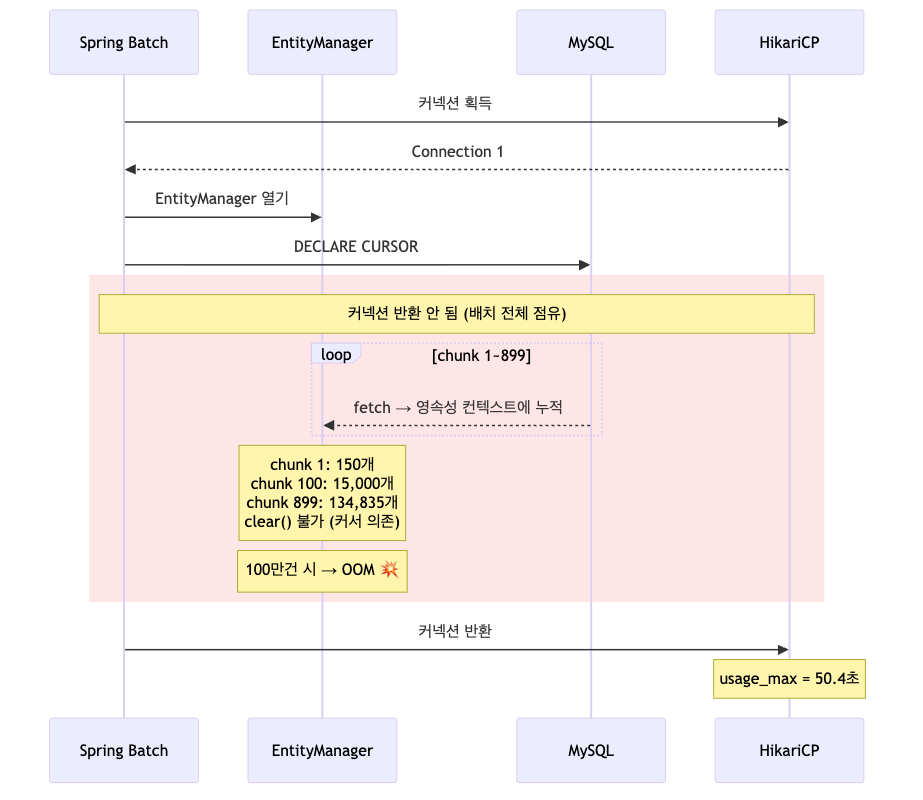
배치가 시작되는 순간 HikariCP에서 커넥션을 받아오고, 그 커넥션 위에서 EntityManager 하나가 열립니다. 이후 DECLARE CURSOR 가 한 번 실행되면 chunk마다 데이터를 fetch 하는데, 그 사이에 EntityManager는 절대 닫히지 않습니다. 그 결과 chunk 1에서 150개, chunk 100에서 15,000개, chunk 899에서 134,835개가 영속성 컨텍스트에 그대로 쌓이게 됩니다. 100만 건으로 가면 약 300만 개의 엔티티가 메모리에 상주하게 되고, 컨테이너 힙이 1GB 수준이라면 그대로 OOM 으로 떨어집니다.
여기서 흥미로운 건 빨간색으로 표시한 구간 전체 동안 HikariCP의 커넥션 1개가 계속 점유 상태로 머문다는 점입니다. 짧은 트랜잭션 여러 번이 아니라 한 번 잡고 안 놓는 구조입니다. 이게 partition 확장을 막는 결정적인 이유였습니다. 같은 구조로 4개 파티션을 띄우면 커넥션 4개가 똑같이 묶입니다.
이 한계 때문에 다른 방식이 필요했습니다.
4. Keyset Paging Reader 직접 구현
Keyset Paging 이란?
페이지를 나누는 두 가지 방식이 있습니다.
OFFSET 방식
1
2
3
4
5
-- 1페이지
SELECT ... LIMIT 1000 OFFSET 0
-- 100페이지
SELECT ... LIMIT 1000 OFFSET 99000
OFFSET 방식은 DB가 매번 처음부터 데이터를 세서 99,000개를 건너뛴 뒤에 다음 1,000개를 가져옵니다. 뒤로 갈수록 비용이 점점 커집니다.
Keyset 방식
1
2
3
4
5
6
7
8
-- 1페이지
SELECT ... WHERE id > 0 ORDER BY id LIMIT 1000
-- 2페이지
SELECT ... WHERE id > 1000 ORDER BY id LIMIT 1000
-- 100페이지
SELECT ... WHERE id > 99000 ORDER BY id LIMIT 1000
Keyset은 직전 페이지의 마지막 id를 기억해 두었다가, 다음 페이지에서 id > lastId 조건으로 인덱스를 바로 점프합니다. 몇 페이지를 가도 비용이 일정합니다.
추가로 우리에게 더 중요한 효과가 있습니다. 각 페이지마다 EntityManager를 새로 열고 닫는 구조로 만들 수 있다는 점입니다. 그러면 Cursor의 영속성 컨텍스트 누적 문제가 자연스럽게 해결됩니다.
직접 구현이 필요했던 이유
Spring Data JPA의 Repository 추상화로는 EntityManager의 생명주기를 직접 제어할 수 없습니다. Spring이 알아서 관리해주기 때문에 페이지마다 EntityManager를 열고 닫는 식의 제어가 불가능합니다.
QueryDSL을 써도 마찬가지입니다. QueryDSL은 결국 EntityManager 위에서 동작하기 때문에, EntityManager 생명주기 관리는 우리가 직접 해야 합니다.
그래서 EntityManagerFactory를 주입받아서 페이지마다 직접 EntityManager를 생성/소멸시키는 Reader를 만들었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
private List<UserStreakItem> fetchNextPage() {
EntityManager em = entityManagerFactory.createEntityManager();
try {
// 1단계: ID만 조회
List<Long> ids = em.createQuery(ID_JPQL, Long.class)
.setParameter("start", start)
.setParameter("end", end)
.setParameter("lastId", lastId)
.setParameter("maxId", maxId)
.setMaxResults(PAGE_SIZE)
.getResultList();
if (ids.isEmpty()) return List.of();
// 2단계: ID 목록으로 엔티티 + 연관관계 fetch
List<Object[]> results = em.createQuery(FETCH_JPQL, Object[].class)
.setParameter("ids", ids)
.getResultList();
return results.stream()
.map(row -> {
UserInfo userInfo = (UserInfo) row[0];
LocalDate firstReviewDate = (LocalDate) row[1];
Long reviewCount = (Long) row[2];
lastId = userInfo.getId();
return new UserStreakItem(userInfo, firstReviewDate, reviewCount);
})
.toList();
} finally {
em.close();
}
}
페이지마다 새 EntityManager를 만들고, finally에서 닫습니다. 닫히는 순간 영속성 컨텍스트도 같이 비워지기 때문에 GC가 회수해갈 수 있습니다.
LEFT JOIN FETCH + LIMIT 의 함정
여기서 한 번 막혔습니다. 처음에는 단일 쿼리로 작성했는데 이런 경고가 떴습니다.
1
2
HHH90003004: firstResult/maxResults specified with collection fetch;
applying in memory
LEFT JOIN FETCH u.osAuthInfo 처럼 컬렉션(OneToMany)에 대한 fetch join + LIMIT 조합이 문제였습니다.
OneToMany는 결과가 행 단위로 펼쳐집니다.
1
2
3
4
user_id=1, osAuthInfo_id=1 ← UserInfo 1개인데 2행으로 펼쳐짐
user_id=1, osAuthInfo_id=2
user_id=2, osAuthInfo_id=3
user_id=3, osAuthInfo_id=4
여기에 LIMIT 1000을 걸면 행 1,000개가 잘릴 뿐 엔티티 1,000개가 잘리는 것이 아닙니다. 그래서 Hibernate는 LIMIT을 DB로 보내지 않고, 결과를 전부 가져온 뒤 메모리에서 자릅니다.
1
2
우리 의도: DB에서 1,000건만 가져와
Hibernate: 100만건 다 가져온 후 → 메모리에서 1,000개 추출 → OOM
또 해결책을 찾다가 StackOverflow에서 추천하는 방법을 발견할 수 있었습니다..
해결 방법은 2단계 쿼리입니다.
| 1단계 | 2단계 | |
|---|---|---|
| 컬렉션 JOIN FETCH | 없음 | 있음 |
| LIMIT | 있음 | 없음 |
| 쿼리 | SELECT u.id ... | SELECT u ... WHERE u.id IN (:ids) |
1단계에서는 컬렉션 fetch 없이 ID만 LIMIT으로 가져오고, 2단계에서는 LIMIT 없이 ID 목록으로 fetch join을 합니다. 이러면 둘 다 정상 동작합니다.
결과
100만 건으로 다시 돌렸습니다.
1
Job: [streakAlertJob] completed in 1m7s003ms

OOM 없이 1분 7초로 완주했습니다. 같은 구조를 그림으로 비교해보면 차이가 분명합니다.
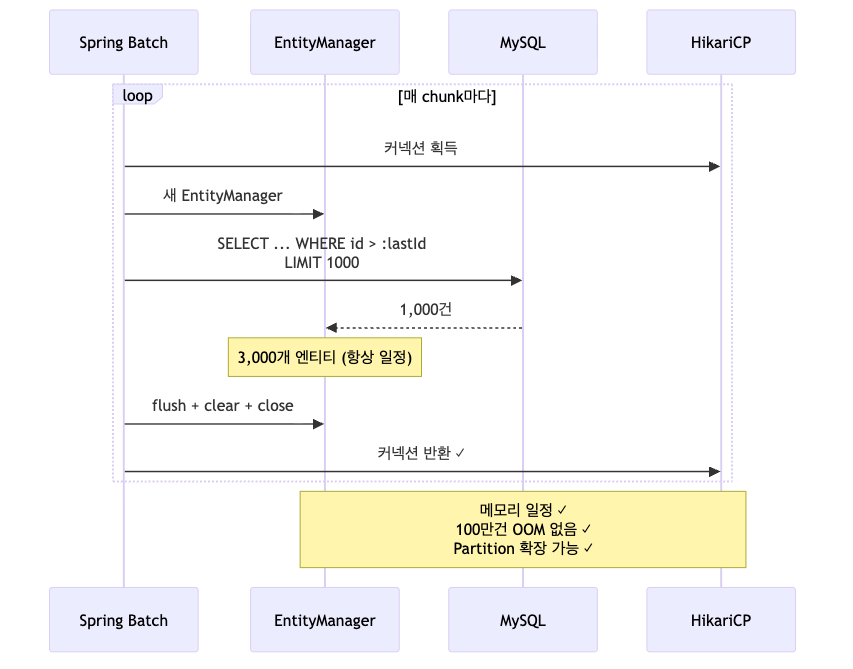
매 chunk 마다 새 EntityManager 를 열고, ID 1,000개를 받아 처리한 뒤, flush + clear + close 를 거쳐 닫아버립니다. 닫히는 순간 영속성 컨텍스트도 같이 사라지기 때문에 GC가 회수해갈 수 있고, HikariCP 커넥션도 즉시 풀로 반환됩니다. 1,000개를 처리하든 100만 개를 처리하든 어느 시점이든 메모리에 올라와 있는 엔티티 수는 거의 일정하게 유지됩니다.
Cursor 방식과 비교해서 두 가지가 핵심적으로 달라졌습니다.
| Cursor | Keyset | |
|---|---|---|
| EntityManager 수명 | 배치 전체 | chunk 단위 |
| 커넥션 점유 시간 | 50초 (배치 전체) | 0.5초 미만 (chunk 단위) |
| 영속성 컨텍스트 | 누적 | 매번 초기화 |
| GC 가능 시점 | 배치 종료 후 | chunk 종료 직후 |
| Partition 확장 | 불가 (커넥션 점유) | 가능 (짧게 잡았다 놓음) |
“Spring Data JPA의 Repository 추상화로는 EntityManager 생명주기를 직접 제어할 수 없어서, JPA EntityManager를 직접 사용해 페이지마다 영속성 컨텍스트를 초기화하는 Keyset Reader를 구현했다.”
이렇게 정리할 수 있게 되었습니다.
다음 글
여기까지가 시즌1입니다.
시즌1에서는 JpaCursorItemReader 의 한계와 Keyset Paging Reader로 OOM을 넘긴 과정까지 정리했습니다.
이 다음부터는 DB 읽기보다 더 큰 병목이었던 외부 I/O, RabbitMQ 분리, Worker concurrency, Partitioning 이야기가 이어집니다.