(MagicOfConch) FCM 알림 배치 100만건 최적화기 - 2
(MagicOfConch) FCM 알림 배치 100만건 최적화기 - 2
MagicOfConch(마법의 소라고동) 프로젝트의 Streak 알림 배치를 단계적으로 개선한 기록입니다. Stack: Spring Batch, JPA, RabbitMQ, Prometheus, Grafana 이 글은 Keyset Paging으로 OOM을 넘긴 이후, 외부 I/O 병목을 어떻게 분리했는지에 대한 기록입니다.
이전 글에서는 JpaCursorItemReader 의 구조적 한계와 Keyset Paging Reader를 직접 구현해서 100만 건을 OOM 없이 끝낸 과정까지 정리했습니다.
5. 더 큰 벽 - 외부 I/O
여기까지는 사실 “DB에서 읽기” 만 측정한 것입니다. 실제 배치는 마지막에 FCM에 푸시 메시지를 보내야 합니다. 그 시간을 어떻게 측정해야 할지 고민했습니다.
Firebase 공식 문서를 찾아봤습니다. (FCM Status Dashboard)
“Latency represents the time to respond to a request to send a message and does not measure the latency to deliver the message to the device.” p95 < 350 ms (30일 롤링 SLO)
FCM HTTP API의 응답 시간이 p95 기준 350ms 이하라는 SLO 입니다. 디바이스 도달 시간이 아니라, “메시지 접수했다” 응답까지의 시간입니다.
직접 서버에서 FCM API를 호출해봤습니다.
1
2
3
4
5
time curl -s -o /dev/null -w "HTTP %{http_code}, Time: %{time_total}s\n" \
-X POST "https://fcm.googleapis.com/v1/projects/.../messages:send" \
-H "Authorization: Bearer $FCM_ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{"message":{"token":"INVALID","notification":{"title":"latency","body":"test"}}}'
1
real 0m0.203s
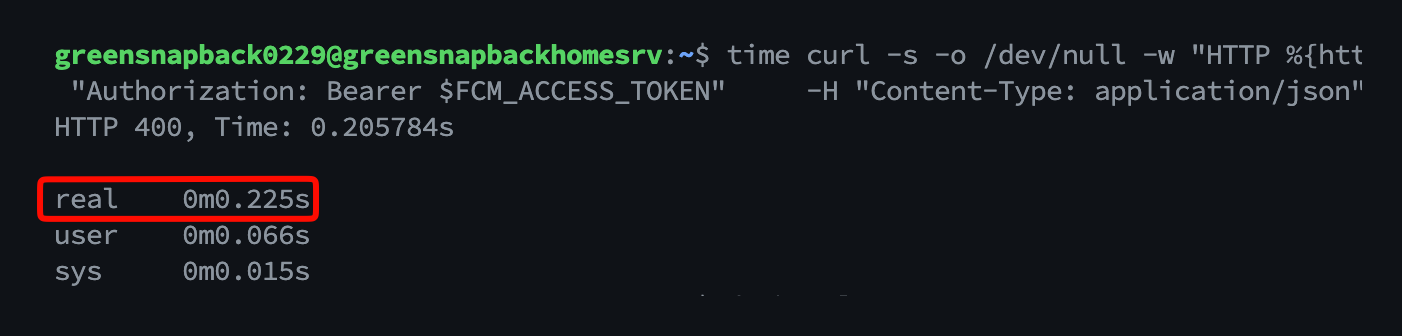
약 203ms. 공식 SLO 안쪽입니다.
이걸 100만 건에 곱하면 어떻게 될까요?
1
1,000,000 × 200ms = 약 56시간
배치에서 직접 FCM을 호출하는 구조는 이 시점에 사형선고를 받았습니다.
Thread.sleep(200)으로 시뮬레이션할까 하다가, 노트북에 webflux 서버를 띄우고 Tailscale로 미니 PC에서 호출하도록 해서 진짜 네트워크 I/O를 측정해봤습니다.
Writer를 RestTemplate 호출로 바꾸고 chunk 1,000건짜리 배치를 돌렸을 때 chunk 하나가 약 50초 걸렸습니다. 100만건 환산하면 약 14시간. Thread.sleep 추정치와 비슷한 수준입니다.
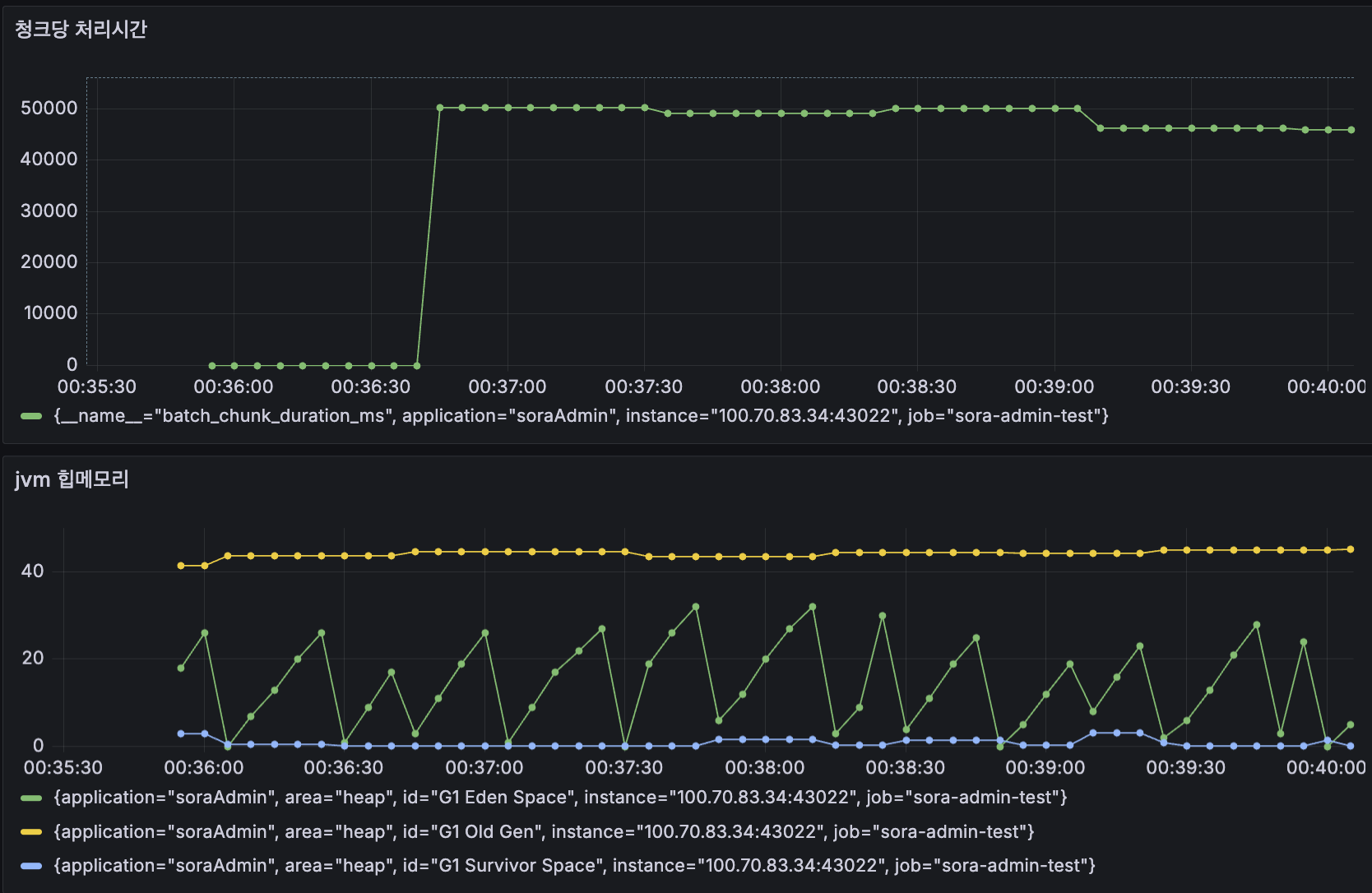
6. 메시지 큐 도입 - RabbitMQ
왜 큐 분리인가
배치에서 하는 일을 다시 보면, 한 행마다 이런 흐름입니다.
1
Reader (DB read) → Processor (메시지 분기) → Writer (FCM 발송)
Reader와 Processor는 빠릅니다. Writer가 외부 API를 호출하면서 200ms씩 블로킹되는 것이 전부입니다. 이걸 한 스레드에서 직렬로 하니까 14시간이 나오는 것입니다.
메시지 큐 패턴 Producer가 메시지를 큐에 던지고, Consumer가 큐에서 꺼내서 처리하는 구조입니다. Producer와 Consumer가 분리되어 있어서, Producer는 큐에 넣자마자 손을 떼고 다음 일을 합니다. Consumer가 느리더라도 Producer는 영향을 받지 않습니다. 외부 I/O가 들어가는 작업을 비동기로 분리할 때 가장 흔히 쓰는 패턴입니다.
배치를 Producer로, 발송 워커를 Consumer로 두면 됩니다. 배치는 메시지를 큐에 넣는 것까지만 책임지고, 실제 FCM 발송은 Worker가 비동기로 처리합니다.
1
2
3
4
[배치] [큐] [Worker]
Reader → ─────→ ─────→
Processor → publish consume FCM 발송
Writer → ─────→ ─────→
배치 입장에서는 외부 I/O를 0초로 보는 셈입니다.
구조
RabbitMQ 컨테이너를 띄우고, batch-worker 라는 별도 모듈을 만들었습니다.
| 컴포넌트 | 역할 |
|---|---|
notification-exchange | direct exchange |
notification-queue | 메인 큐 |
notification-queue.dlq | retry 3회 실패 시 이동 |
notification.streak | routing key |
소라어드민(Producer)에서는 Writer가 RabbitMQ에 publish 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Component
@RequiredArgsConstructor
public class StreakWriter implements ItemWriter<FcmRequest> {
private final RabbitTemplate rabbitTemplate;
@Value("${rabbitmq.notification.exchange}")
private String exchange;
@Value("${rabbitmq.notification.routing-key}")
private String routingKey;
@Override
public void write(Chunk<? extends FcmRequest> chunk) throws Exception {
for (FcmRequest request : chunk) {
rabbitTemplate.convertAndSend(exchange, routingKey, request);
}
}
}
배치 워커 모듈에서는 @RabbitListener로 큐를 구독합니다.
1
2
3
4
@RabbitListener(queues = "${rabbitmq.notification.queue}")
public void consumeAndSendFcm(FcmRequest request) {
fcmUtil.send(request);
}
100만 건을 다시 돌렸을 때 배치가 publish를 끝내는 시간은 약 2분 이었습니다. Reader + Processor 시간이 거의 그대로 찍힌 셈입니다.
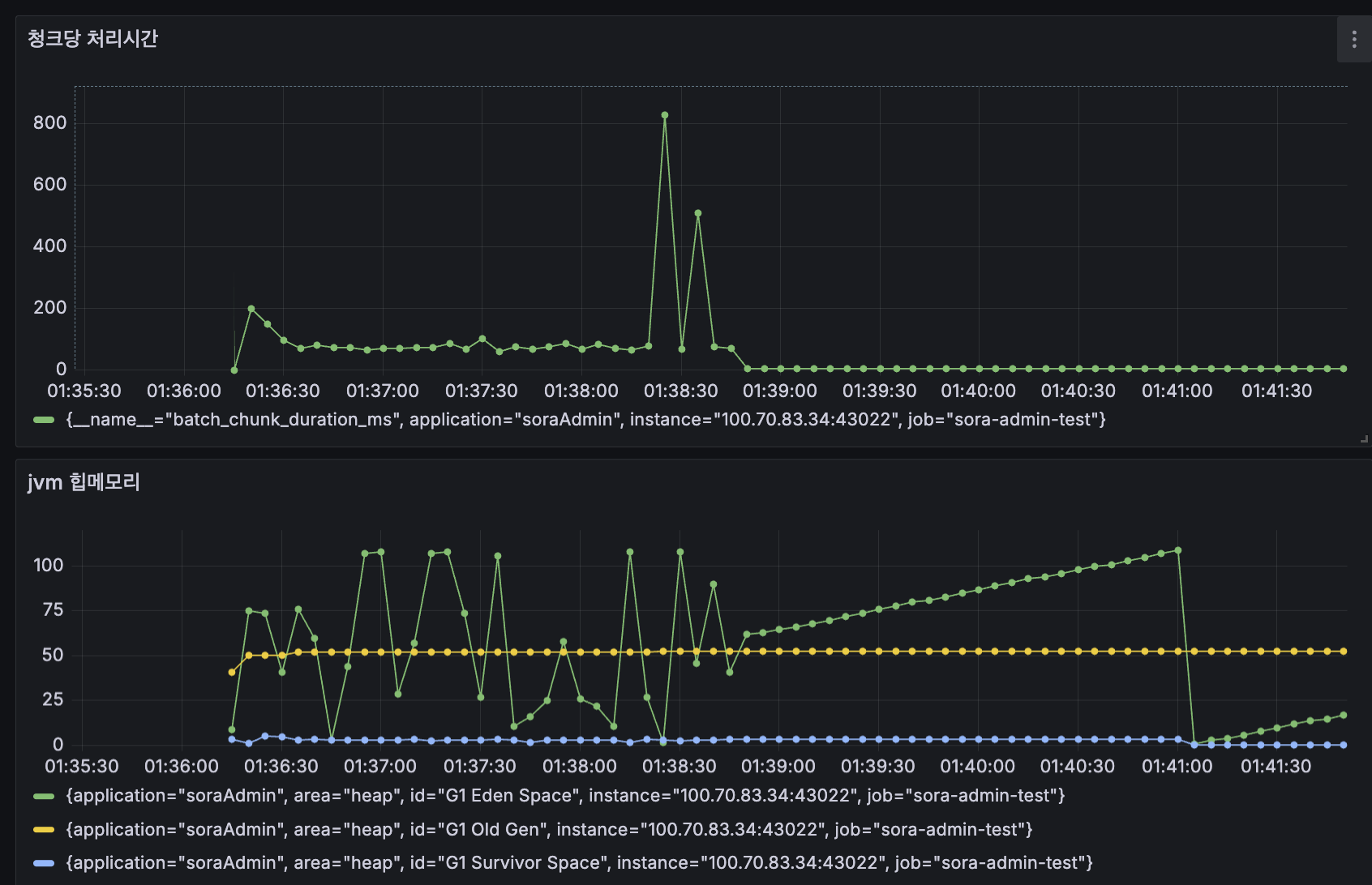
배치는 빨리 끝났지만, 실제 발송 책임은 Worker가 가져갑니다. 이제 Worker의 처리 속도를 어떻게 올릴지 가 다음 문제입니다.
7. Worker concurrency 튜닝
Worker가 단일 스레드로 메시지를 하나씩 가져와서 처리하면 결국 56시간이 됩니다. RabbitMQ Listener의 concurrency를 올려서 동시에 여러 건을 처리하게 만들어야 합니다.
prefetch 와 concurrency
- prefetch : Consumer가 한 번에 큐에서 가져오는 메시지 수입니다. 50이면 한 번에 50개를 받아 자기 메모리에 두고 처리합니다.
- concurrency : Listener의 동시 처리 스레드 수입니다. 5로 설정하면 5개 스레드가 병렬로 메시지를 처리합니다.
Worker의 작업이 CPU 연산이 아니라 네트워크 I/O 대기라면, CPU 코어 수보다 스레드를 더 올려도 효과가 있습니다. I/O 대기 중에는 스레드가 CPU를 안 쓰니까요.
처음엔 적용이 안 됐던 이슈
application.yml에서 concurrency 값을 설정했는데도 Worker는 스레드 1개로만 동작했습니다.
1
2
3
4
5
6
spring:
rabbitmq:
listener:
simple:
concurrency: 10
max-concurrency: 15
원인은 SimpleRabbitListenerContainerFactory를 직접 Bean으로 정의해 두었기 때문이었습니다. Spring Boot의 자동 설정이 사용자 정의 Factory가 있으면 비활성화되면서 application.yml 설정이 무시되는 것이었습니다.
Spring AMQP 공식 문서를 찾아봤습니다.
“If a
MessageConverterbean is defined, it is associated automatically to the auto-configuredAmqpTemplate.”
Factory를 직접 만들 필요가 없었습니다. MessageConverter Bean 하나만 정의해두면 Spring Boot가 자동으로 연결해줍니다. JSON 역직렬화가 필요해서 Factory를 만들었던 것이었는데, 그건 MessageConverter Bean만으로 충분했던 것이었습니다.
Factory를 삭제하고 Bean을 정리했습니다.
1
2
3
4
@Bean
public MessageConverter jsonMessageConverter() {
return new Jackson2JsonMessageConverter();
}
이제 application.yml의 concurrency, prefetch, retry 설정이 자동으로 반영됩니다.
측정
같은 방식으로 1만 건짜리 데이터를 두고 concurrency 값만 바꿔가면서 측정했습니다. (Worker는 0.5 CPU / 512MB 컨테이너)
| concurrency | 소요 시간 | rate (msg/s) | 개선율 |
|---|---|---|---|
| 1 | 367초 | 27 | baseline |
| 5 | 95초 | 105 | 3.9배 |
| 7 | 79초 | 126 | 4.7배 |
| 10 | 65초 | 153 | 5.7배 |
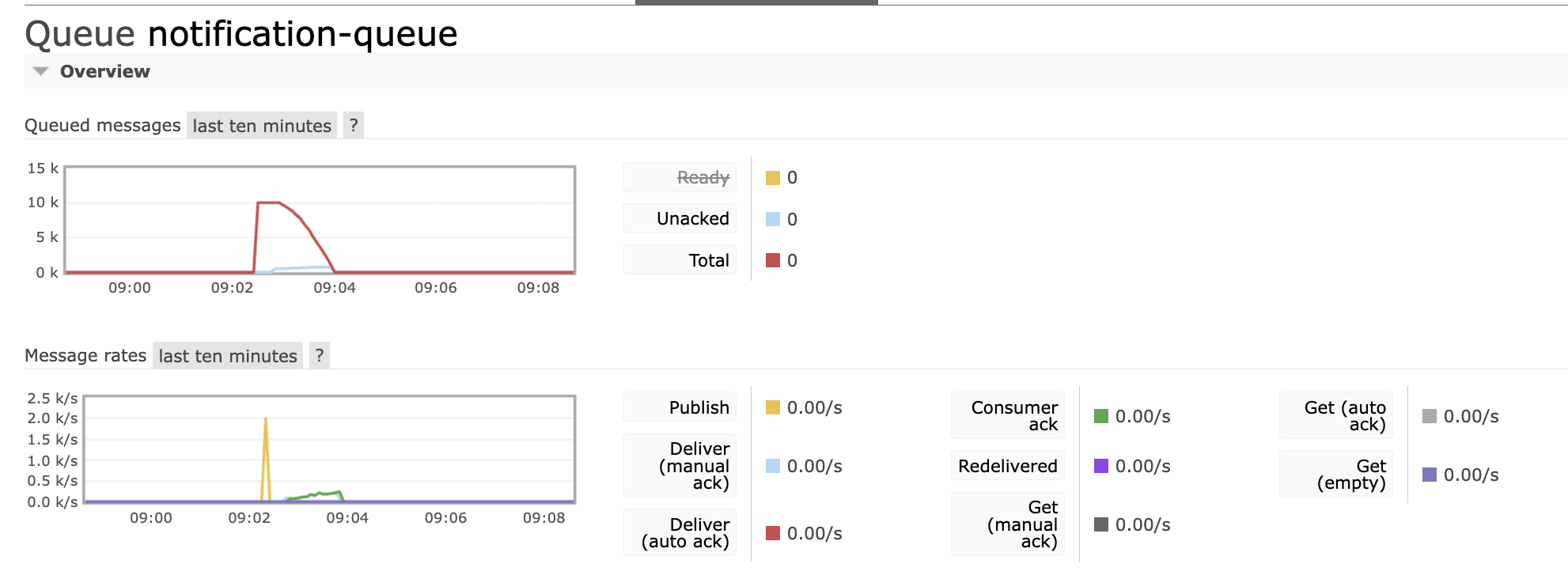
스레드를 늘릴수록 빨라지지만 수확 체감(diminishing returns)이 보입니다.
1
2
3
1 → 5 : +78 msg/s (스레드당 +15.6)
5 → 7 : +21 msg/s (스레드당 +10.5)
7 → 10 : +27 msg/s (스레드당 +9.0)
CPU 0.5코어인데도 concurrency 10에서 단일 스레드 대비 5.7배 빨라졌습니다. 작업이 I/O bound인 덕분입니다. 그 이상은 컨텍스트 스위칭 비용과 webflux 수신 서버 처리량이 따라주지 않아서 효과가 줄어듭니다.
10으로 고정했습니다.
8. 배치도 병렬로 - Spring Batch Partitioning
Worker는 빨라졌지만, 아직 배치 자체(=Producer)는 단일 스레드입니다. 100만 건 publish가 약 2분 걸리는데 이걸 더 줄이고 싶었습니다.
Spring Batch Partitioning 이란? 하나의 Step을 N개의 Worker Step으로 쪼개어 병렬 실행하는 구조입니다. Manager Step이 Partitioner를 통해 데이터 범위를 N등분 한 뒤, TaskExecutor로 각 Worker Step을 동시에 실행합니다. 각 Worker Step은 자기 범위만 Reader → Processor → Writer 합니다.
1
2
3
4
5
6
Manager Step
│
┌───────────┼───────────┐
▼ ▼ ▼
Worker Step Worker Step Worker Step
(id 1~250K) (250K~500K) (500K~750K)
Partitioner에서 user_id의 min/max를 구해서 N등분 했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public class StreakPartitioner implements Partitioner {
private final EntityManagerFactory entityManagerFactory;
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Long minId = ...;
Long maxId = ...;
long range = (maxId - minId) / gridSize + 1;
Map<String, ExecutionContext> partitions = new HashMap<>();
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putLong("minId", minId + (range * i));
context.putLong("maxId", ...);
partitions.put("partition" + i, context);
}
return partitions;
}
}
Reader에서는 stepExecutionContext에서 minId, maxId를 받아서 자기 범위만 읽도록 했습니다.
효과가 없었다
기대했던 것과 다르게 파티션 1개와 3개의 시간이 거의 같았습니다.
1
2
3
Partition 1 : 1m 49s
Partition 3 : 1m 41s
Partition 5 : 1m 41s
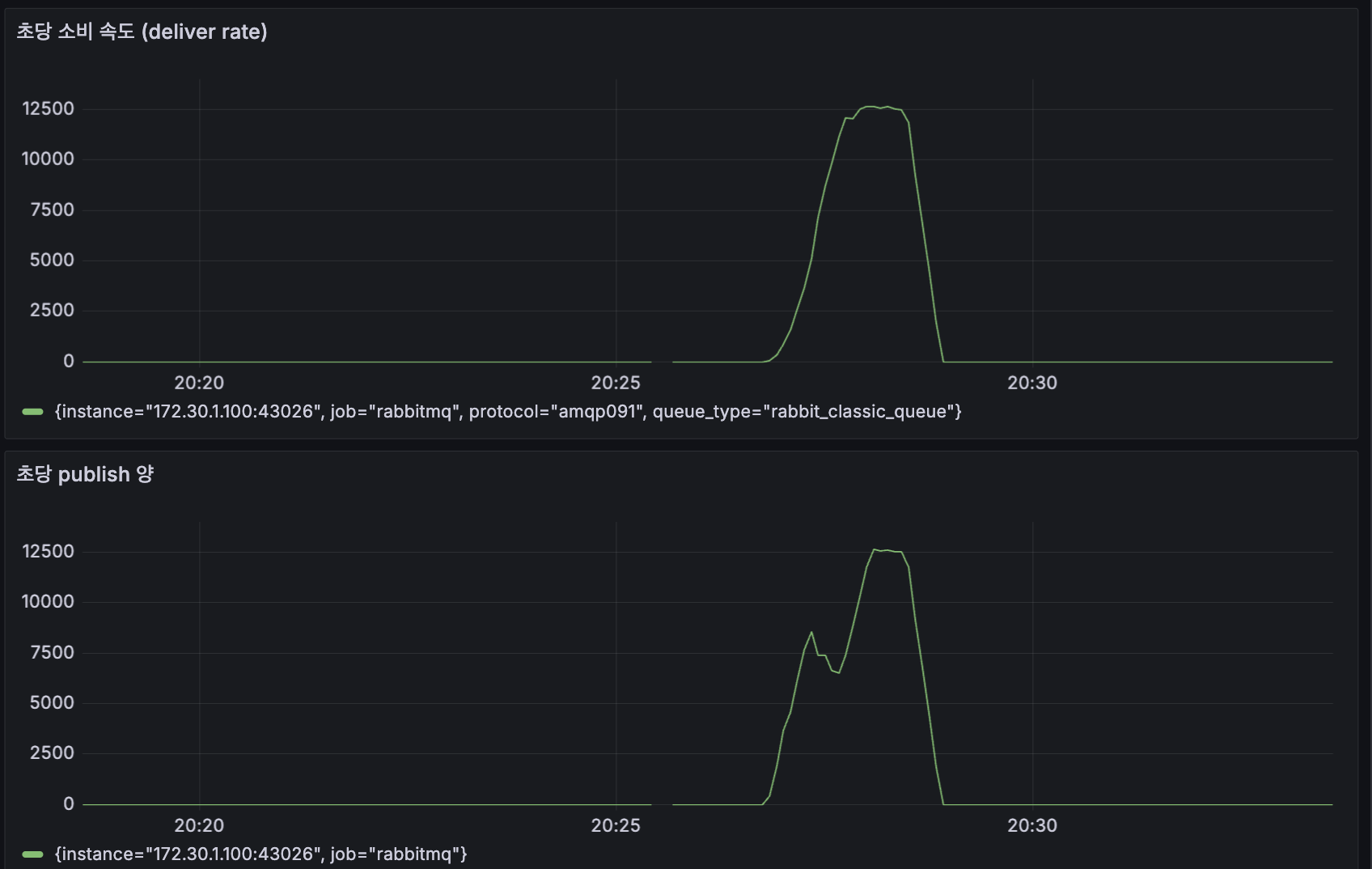
3개 이상 늘려도 거의 줄지 않았습니다. 왜일까?
첫 번째 원인 - RabbitMQ 커넥션 공유
Spring AMQP의 기본 CachingConnectionFactory는 커넥션 1개를 공유하고 채널만 캐싱하는 구조입니다.
AMQP connection vs channel
- Connection : RabbitMQ 브로커와의 TCP 연결입니다.
- Channel : 하나의 connection 위에서 다중화되는 가상 통신 경로입니다.
여러 채널을 만들면 같은 TCP 연결을 공유하게 됩니다. 동시 publish가 많을 때는 채널이 아무리 많아도 결국 같은 TCP 소켓을 직렬로 통과해야 합니다.
1
2
3
4
파티션 Thread 1 ─┐
파티션 Thread 2 ─┤→ Connection 1개 → RabbitMQ
파티션 Thread 3 ─┤ (채널만 여러 개)
파티션 Thread 4 ─┘
고속도로 1차선에 차 4대가 줄 서 있는 셈이었습니다.
spring.rabbitmq.cache.connection.mode 를 connection 으로 바꿔서 파티션 수만큼 별도 커넥션을 만들도록 했습니다.
1
2
3
4
5
6
spring:
rabbitmq:
cache:
connection:
mode: connection
size: ${BATCH_PARTITION_GRID_SIZE:1}
두 번째 원인 - 단일 MySQL CPU
Connection을 분리해도 시간은 거의 그대로였습니다. 파티션을 늘리면 chunk timing 로그에 가끔씩 1~5초 짜리 스파이크가 찍혔습니다.
1
2
3
4
chunk=985, duration=701ms
chunk=974, duration=265ms
...
chunk=132, duration=5362ms ← 5초 스파이크
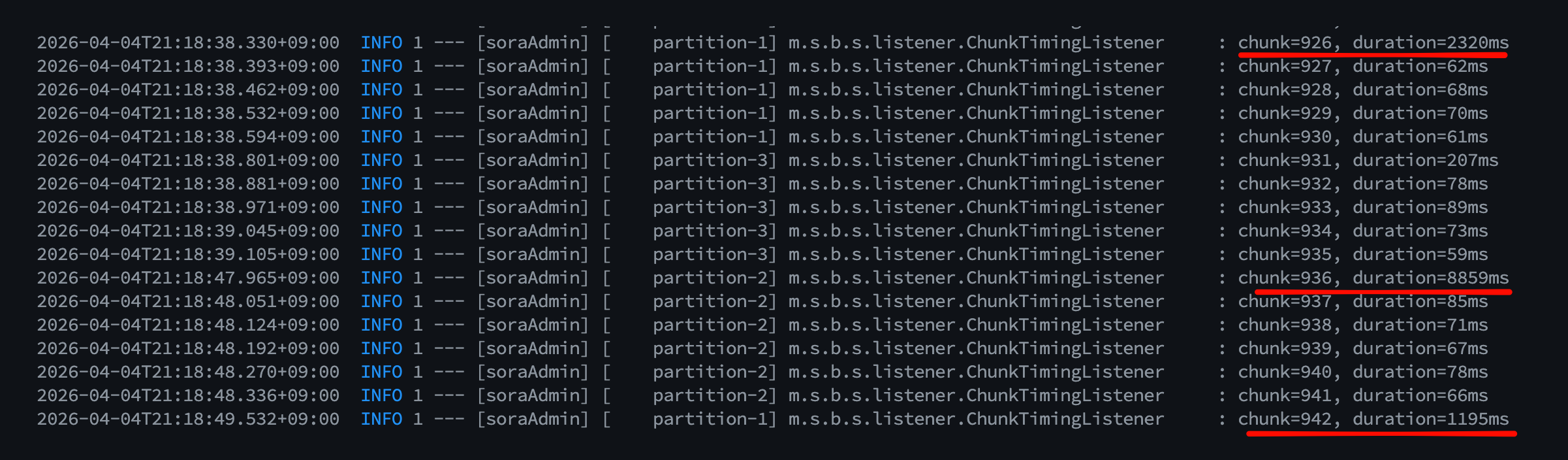
원인은 MySQL이었습니다. 컨테이너 MySQL이 1 CPU 에 buffer pool 128MB 였고, 여러 파티션 스레드가 동시에 쿼리를 날리면서 CPU와 디스크 I/O 경합이 생겼습니다.
이 가설을 검증하려고 몇 가지를 시도했습니다.
- MySQL 버퍼풀을 2GB로 증설 → 거의 차이 없음 (1m 37s → 1m 36s)
- review 집계를 임시 테이블에 미리 저장 (서브쿼리 제거) → 거의 차이 없음 (1m 37s)
이 시점에 의문이 들었습니다. 정말 RabbitMQ publish가 문제인 걸까? 아니면 DB 읽기 자체가 한계인 걸까?
마지막 검증 - Writer 제거
Writer의 publish 코드를 통째로 주석 처리하고 Reader + Processor만 측정해봤습니다.
1
2
3
4
5
6
@Override
public void write(Chunk<? extends FcmRequest> chunk) throws Exception {
// for (FcmRequest request : chunk) {
// rabbitTemplate.convertAndSend(exchange, routingKey, request);
// }
}
1
Step: [workerStep] executed in 37s266ms
DB만 읽으면 37초인데, RabbitMQ에 publish까지 하면 1분 37초. 그 차이가 publish 비용입니다.
근데 결국 DB를 그냥 다 읽는 것만 해도 37초가 걸린다는 점에서 진짜 한계는 여기였습니다. 4 CPU 환경에서 단일 MySQL 인스턴스로 100만 건을 읽는 시간 자체가 이미 충분히 큰 것이었습니다.
9. 결론 - 환경의 한계
최종 아키텍처
이 모든 과정을 거쳐서 최종적으로 만들어진 구조는 다음과 같습니다.
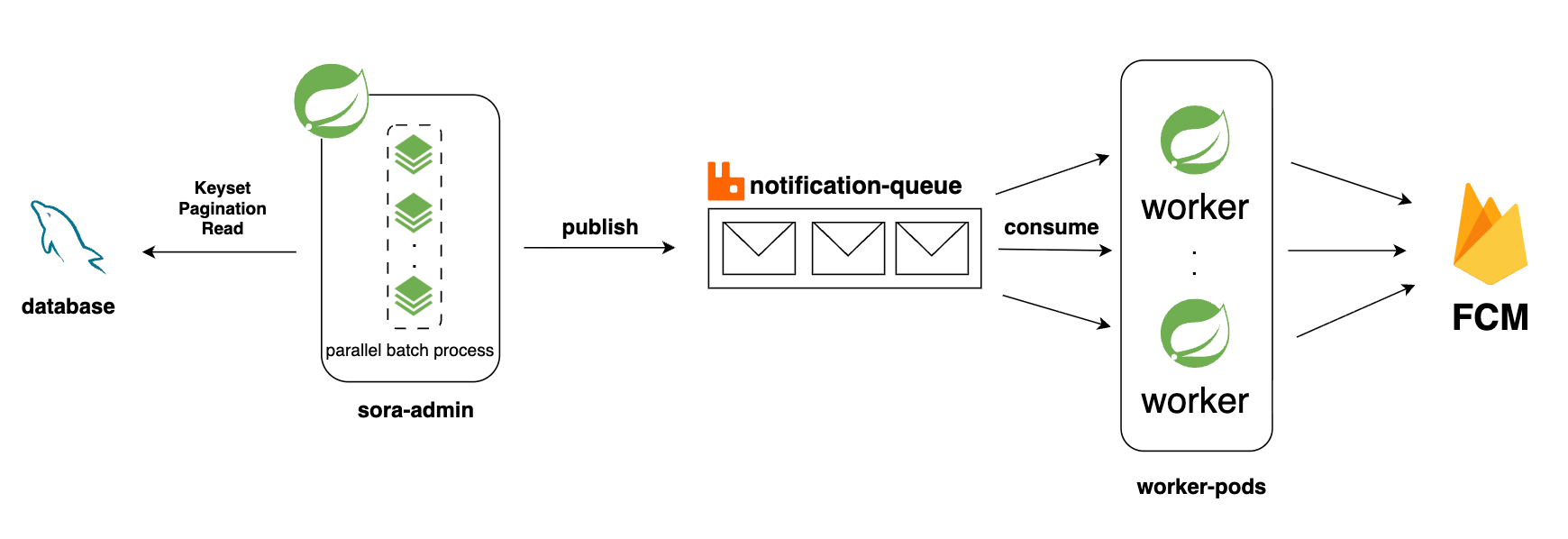
배치(Producer)는 Keyset Paging으로 DB에서 읽어 RabbitMQ에 publish 까지만 책임지고, Worker(Consumer)가 큐에서 꺼내서 FCM 발송을 담당합니다. 배치는 파티셔닝으로 병렬화 가능하고, Worker는 concurrency 튜닝과 컨테이너 스케일 아웃으로 처리량을 늘릴 수 있습니다.
단계별 결과
각 단계의 결과를 정리하면 이렇습니다.
| 단계 | 대상 | 결과 |
|---|---|---|
| Cursor + Processor 조회 | 44,945건 | 1분 6초 (baseline) |
| Processor 조회 제거 (서브쿼리) | 44,945건 | 22초 |
| Cursor | 1,000,000건 | OOM |
| Keyset Paging | 1,000,000건 | 1분 7초 |
| Writer + 외부 I/O (가정) | 1,000,000건 | 약 14시간 |
| Queue 분리 (RabbitMQ) | 1,000,000건 | 약 2분 (publish 기준) |
| Worker concurrency 1 | 10,000건 | 367초 |
| Worker concurrency 10 | 10,000건 | 65초 |
| Partition 1 | 1,000,000건 | 1분 49초 |
| Partition 3 | 1,000,000건 | 1분 41초 |
| Partition 5 | 1,000,000건 | 1분 41초 |
코드 레벨에서 할 수 있는 것은 전부 한 것 같습니다.
- Processor의 per-item 조회 : Reader 서브쿼리로 흡수
- OOM : Cursor → Keyset Paging
- 외부 I/O 병목 : Queue 분리
- Worker 처리량 : concurrency 튜닝
- Producer 처리량 : Partitioning + Connection 분리
마지막 한 단계, 단일 MySQL의 처리량을 넘어서는 부분만 남았습니다. 이건 코드가 아니라 인프라 스케일업 영역입니다. CPU를 더 주거나, Read Replica를 분리하거나, 클라우드 RDS처럼 충분한 리소스가 있는 환경으로 옮기는 것이 다음 단계입니다.
회고
이번 작업은 단순히 “배치를 빨리 만들었다” 는 결과가 아니라, 각 단계에서 병목이 어디인지를 측정으로 증명하는 과정이었던 것 같습니다.
Cursor가 OOM이 났을 때도 “메모리를 늘려야지” 가 아니라 “왜 메모리에 쌓이는가?” 를 따라가서 영속성 컨텍스트와 커서의 구조적 딜레마까지 도달했습니다. Partition이 효과가 없었을 때도 “왜?” 를 계속 물어서 RabbitMQ 커넥션 공유 → 단일 MySQL 까지 내려갔습니다.
특히 마지막에 Writer를 제거하고 Reader만 측정해본 게 결정적이었던 것 같습니다. RabbitMQ 탓을 하다가 사실은 DB가 한계였다는 걸 측정 한 번으로 알게 됐으니까요. 측정 없이 추측만 했다면 며칠을 더 헤맸을지도 모릅니다.
또 한 가지 배운 게 있습니다. 처음엔 Spring AMQP의 SimpleRabbitListenerContainerFactory를 직접 Bean으로 만들었었는데, 그게 자동 설정을 가로채서 application.yml의 concurrency 설정이 무시되고 있었습니다. AI에게 물어봤을 때는 Factory에 @Value를 더 받으라고 했었는데, 직접 공식 문서를 찾아보니 MessageConverter Bean만 정의하면 자동으로 연결되는 거였습니다. Factory를 굳이 만들 필요가 없었던 것이었습니다. 처음으로 AI보다 공식 문서가 정답이었던 케이스였습니다 ㅋㅋ
지금은 4코어 미니 PC라서 한계가 있지만, 곧 데스크탑(5800X / 32GB)에 RDS급 환경을 흉내내서 다시 측정해볼 예정입니다. 그 때는 진짜로 100만 건을 1분 안에 끝낼 수 있을지 궁금합니다.
정리
- 코드 레벨 최적화는 Processor의 per-item 조회 제거 → Cursor 한계 → I/O 병목 → 동시성 → 파티셔닝 순으로 풀 수 있습니다.
- 각 단계마다 병목을 추측하지 말고 측정해야 합니다. Prometheus + Grafana, 그리고 가끔은 Writer를 통째로 주석 처리하는 것 같은 단순한 실험이 가장 효과적입니다.
- Cursor 방식의 Reader는 영속성 컨텍스트 + 커서 의존이라는 구조적 딜레마 때문에 대용량에 부적합합니다. Keyset Paging이 정답이지만, JPA Repository로는 EntityManager 생명주기를 직접 제어할 수 없어서 Reader를 직접 만들어야 합니다.
- 외부 I/O가 들어가는 작업은 배치에서 직접 호출하지 말고 큐로 분리하는 게 정답입니다. 배치는 publish 까지만 책임지고, 발송은 Worker에게 맡깁니다.
- 분산 스레드/파티션 최적화는 그 다음 단계의 한계(브로커 커넥션, DB CPU)를 그대로 드러냅니다. 코드가 아니라 인프라가 답인 영역도 있다는 걸 인정해야 합니다.