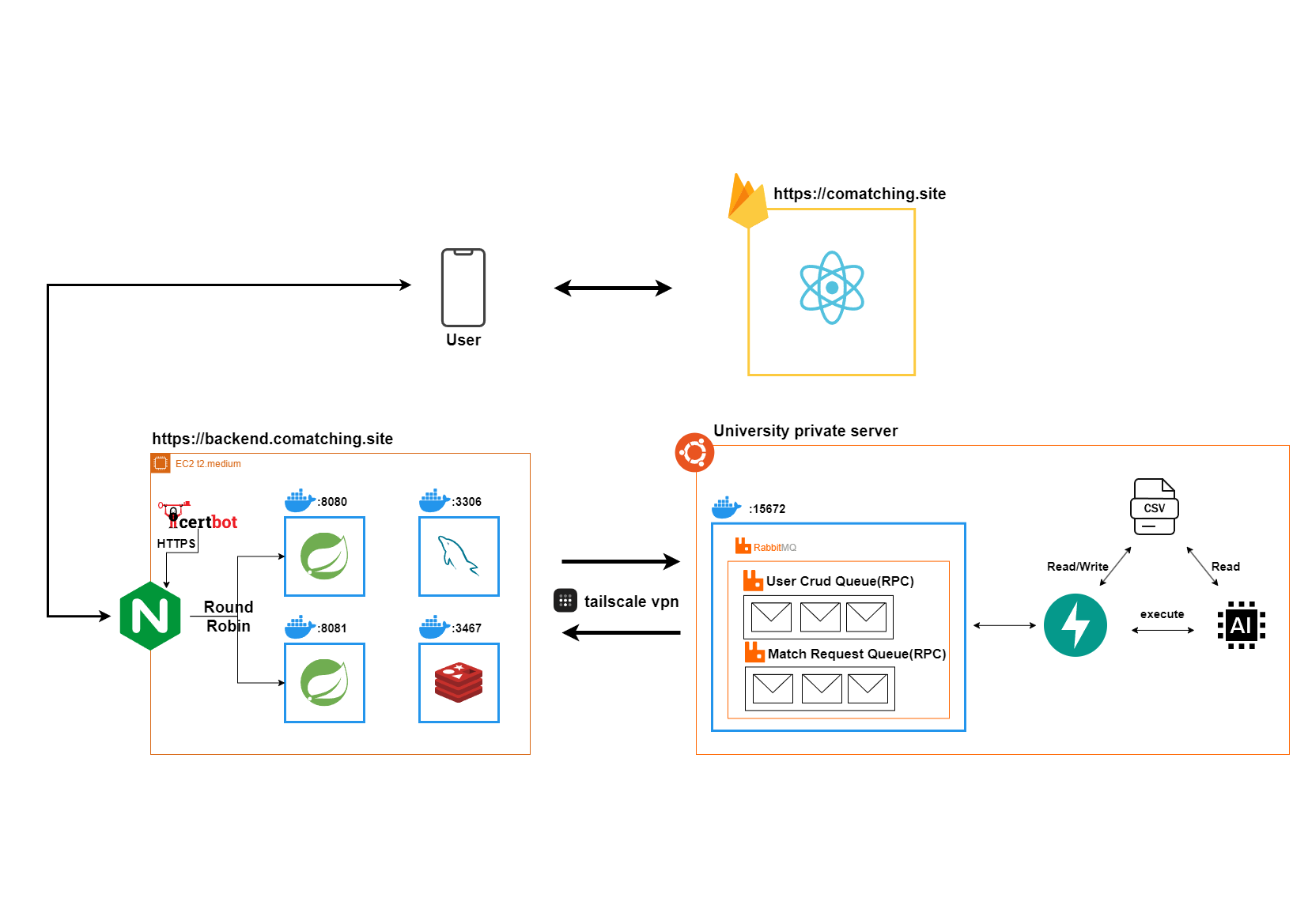
[COMAtching] Ver3 아키텍처
아키텍처 개요
| 구분 | 기술 |
|---|---|
| FE | React, Vite |
| BE | Spring, FastAPI |
| DB | Mysql, Redis, CSV |
| Middle | RabbitMQ |
| Deploy | Docker, Firebase, |
| proxy | Nginx |
| VPN | tailscale |
AI, BE 서버분리
🧱 AI 모델의 과중화
매칭 추천 AI의 고도화로 인해 모델이 더 높은 컴퓨팅 리소스를 요구하게 되었습니다. 초기에는 EC2 프리 티어(t2.micro) 인스턴스에서 BE 서버에 내장된 AI 모델을 실행했지만, 해당 환경은 이미 Docker, Nginx 등 여러 서버가 동작하며 메모리 사용률이 기본적으로 80%에 달하는 상태였습니다. 이미 SWAP 메모리까지 사용하는 상황에서 AI 모델을 실행할 때마다 리소스 한계로 인해 EC2 인스턴스가 중단되는 문제가 빈번히 발생했습니다.
※ 프리티어 메모리가 물리적으로 1GB이고
SWAP을 2GB 정도나 잡았음에도 부족해지는 상황 발생(추가적인 swap은 너무 많은 문맥교환이 발생될 것이고 무리한 상황이라고 판단)
마침 대학교의 좋은 서버를 사용할 수 있는 기회가 생겼고 AI 모델을 실행시키기에 넉넉한 리소스(RAM 16GB)를 가지고 있었습니다.
결과적으로 AI 모델과 BE 서버의 분리가 필요해졌습니다.
📌 그냥 전체적으로 학교서버로 이전해도 되지 않나?
당연하게도 전체 시스템의 이전도 고려했습니다. 하지만 학교망은 여러 공유기와 라우터를 거쳐 다중 NAT되고 있었습니다. 학교 내부망의 관리 권한이 없었기에 원하는 포트포워딩이 불가능했습니다. 따라서 공인 IP를 고정적으로 사용 가능하고 포트포워딩 등 자유로운 네트워크 설정이 가능한 AWS EC2는 여전히 필수적이었습니다. 결국 EC2에 학교 서버를 연결하는 방법이 필요했고 tailscale vpn을 사용하여 가상 내부망으로 통신이 가능했습니다.
✏ 여전히 요구되는 CSV 관리
COMAtching의 AI는 CSV 파일을 참고하여 모델이 동작합니다. CSV 파일에는 각 유저의 식별값과 매칭에 필요한 정보가 조건에 맞게 DB와 동일하게 있어야합니다. 이를 관리하기 위해 분리된 서버에서 AI 모델을 실행시키고 CSV를 관리해줄 수 있는 BE가 필요했습니다. CSV에 많은 양의 데이터가 담길 것으로 예상되었기 때문에 효율적으로 CSV 파일을 관리할 수 있는 Python 기반의 pandas를 고려했습니다. 같은 Python언어를 사용할 수 있는 서버 프레임워크로 fastAPI를 통해 AI 관리 BE 서버를 개발했습니다.
Message Queue 도입
2개의 백엔드 서버로 분리되면서 비동기적으로 통신할 방법이 필요했고 자연스럽게 메세지 지향 미들웨어(MOM)를 고려하게 되었습니다.
첫 도입이고 학생이기에 무료이면서 레퍼런스가 많고 쉽게 접근할 수 있는 기술들을 후보로 두고 고민을 시작했습니다.
두 백엔드 서버간 구현되어야할 기능은 크게 2가지 였습니다.
- 매칭 요청 및 결과 응답
- CSV에 유저 데이터 반영(CRUD)
Kafka
최근 대규모 분산 데이터 처리에서 굉장히 각광받는 핫한 기술이었습니다 다음과 같은 장점이 있었습니다.
- 메시지 로그를 디스크에 저장하여 유실 방지 및 재처리가 가능.
- Pub/Sub 모델을 통해 데이터의 발행과 구독이 용이.
- 높은 처리량과 대규모 트래픽 처리에 적합.
그러나 프로젝트 규모와 요구사항을 고려했을 때 다음과 같은 단점이 있었습니다.
- 초기 설정과 운영 비용이 너무 과중.
- 요구 트래픽 수준에서는 오버 엔지니어링 가능성.
- 응답이 필요한 상황에서는 MSA 디자인 패턴을 적용해야 할 추가 개발 요소가 발생.
Redis
Redis Pub/Sub는 메모리 기반 메시징 미들웨어로, 다음과 같은 장점이 있었습니다:
- 고속 메시지 처리로 실시간 통신이 가능.
- Pub/Sub 모델을 지원하여 간단한 통신 구현이 가능.
- 하지만 몇 가지 단점이 문제로 작용했습니다:
하지만 인메모리에서 동작하고 전달보장이 되지 않아 안정성이 너무 낮다고 판단되었습니다.
빠른 처리가 필요한 단순 메시지 전송에는 적합하지만, 적어도 사용자의 포인트를 사용하는 매칭 기능에 결합되는 만큼 안정성을 고려해야했습니다.
RabbitMQ
selected
RabbitMQ는 프로젝트 요구사항에 가장 부합하는 선택지였습니다. 특히, 다음과 같은 이유로 RabbitMQ를 도입하게 되었습니다.
- 다양한 비동기 통신 패턴 지원: Pub/Sub, Work Queue, 그리고 프로젝트에서 요구한 RPC 패턴도 구현 가능.
- Ack/Nack 메커니즘: 메시지 전달 보장 및 실패 시 재처리가 가능해 안정적인 통신 관리 가능.
- 적은 초기 도입 비용: Kafka와 비교했을 때 설치 및 설정이 훨씬 간단.
- 적정 성능: 대규모 분산 환경이 아니었기에 Redis나 Kafka보다 적합.
RabbitMQ는 매칭 서비스, CSV 사용자 반영 기능의 요청-응답 처리와 안정적인 데이터 전송에 적합했으며 , Redis와 Kafka의 장점을 균형있게 가져갈 수 있는 선택지라고 판단했습니다.
Nginx
- 비동기 이벤트 기반의 아키텍처를 가지고 있어서 축제 이벤트와 같은 동시에 많은 유저들이 연결을 효율적으로 처리할 수 있다고 판단했습니다.
- 리버스 프록시를 통해 프록시 서버만 노출하여 안정성을 확보할 수 있었고 로드밸런싱으로 추후 효율적인 서버의 확장 가능성을 고려했습니다.
Let's Encrypt과 연동하여 SSL/TLS 적용을 무료로 할 수 있었습니다.