(COMAtching) OpenAI 연동 비동기 AI 토큰 스트리밍 개선
(MagicOfConch) OpenAI 연동 비동기 AI 토큰 스트리밍 개선
MagicOfConch(마법의 소라고동) 프로젝트의 리뷰 토큰 스트리밍 기능을 개선하는 과정에 대한 글입니다. Stack: Spring-Boot, Webflux, Asynchronous
상황
⚙️ 어떤 기능인가?

리뷰 서비스는 사용자가 회고(or 일기)를 작성하면 사용자가 선택한 MBTI T(현실적 조언)/F(감정적 공감) 타입으로 튜닝된 LLM을 호출하여 AI의 리뷰를 ‘토큰 단위‘로 실시간 스트리밍 후 서버에 저장하는 기능입니다.
💭 토큰 스트리밍..?
토큰은 언어 모델이 텍스트를 이해하고 생성하는 기본 단위입니다. ChatGPT를 웹으로 접근하여 사용해보면 사용자가 프롬프트를 작성하고 답을 요청하면, GPT는 한번에 모든 글자가 올라오는 것이 아니라 마치 한글자씩 전송되는 것처럼 보입니다.
LLM 모델이 토큰 단위로 응답을 생성해서 실시간으로 받아오는 것이라고 생각하면 됩니다.
실시간으로 받아왔을때의 장점으로는 응답 토큰을 모두 기다렸다가 하나의 응답 문자열로 오는 것보다 빠르게 실시간으로 응답을 확인할 수 있다는 것입니다.
응답이 길어지게 되면 2-3초 정도로 생각보다 긴 시간을 사용자가 대기해야 했기 때문에 실시간 스트리밍 구현은 중요한 요구사항이었습니다.
OpenAI API도 Streaming 기능을 지원합니다. ( 공식 API Docs )
기존 구현
OpenAI를 호출하고 실시간 토큰 스트리밍을 적용하기 위해서 Spring 공식 프레임워크인 Spring-AI의 ChatClient를 활용했습니다.
ChatClient는 LLM 호출용 객체로 아래와 같은 작업들을 Spring 개발자에게 친숙한 형태로 제공합니다.
- HTTP 요청 직접 구성
- API Key 관리
- 모델별 요청 포맷 차이 처리
- 스트리밍 처리
- 메시지(role, content) 구조 관리
현재는 서버가 분리되어 있지만 프로젝트 초기에는 규모가 적어 단일 서버로 운영했기 때문에 review 서버를 따로 두지않고 MVC 기반의 서버에서 해당 기능을 제공하도록 구현했습니다.
🎥 시나리오
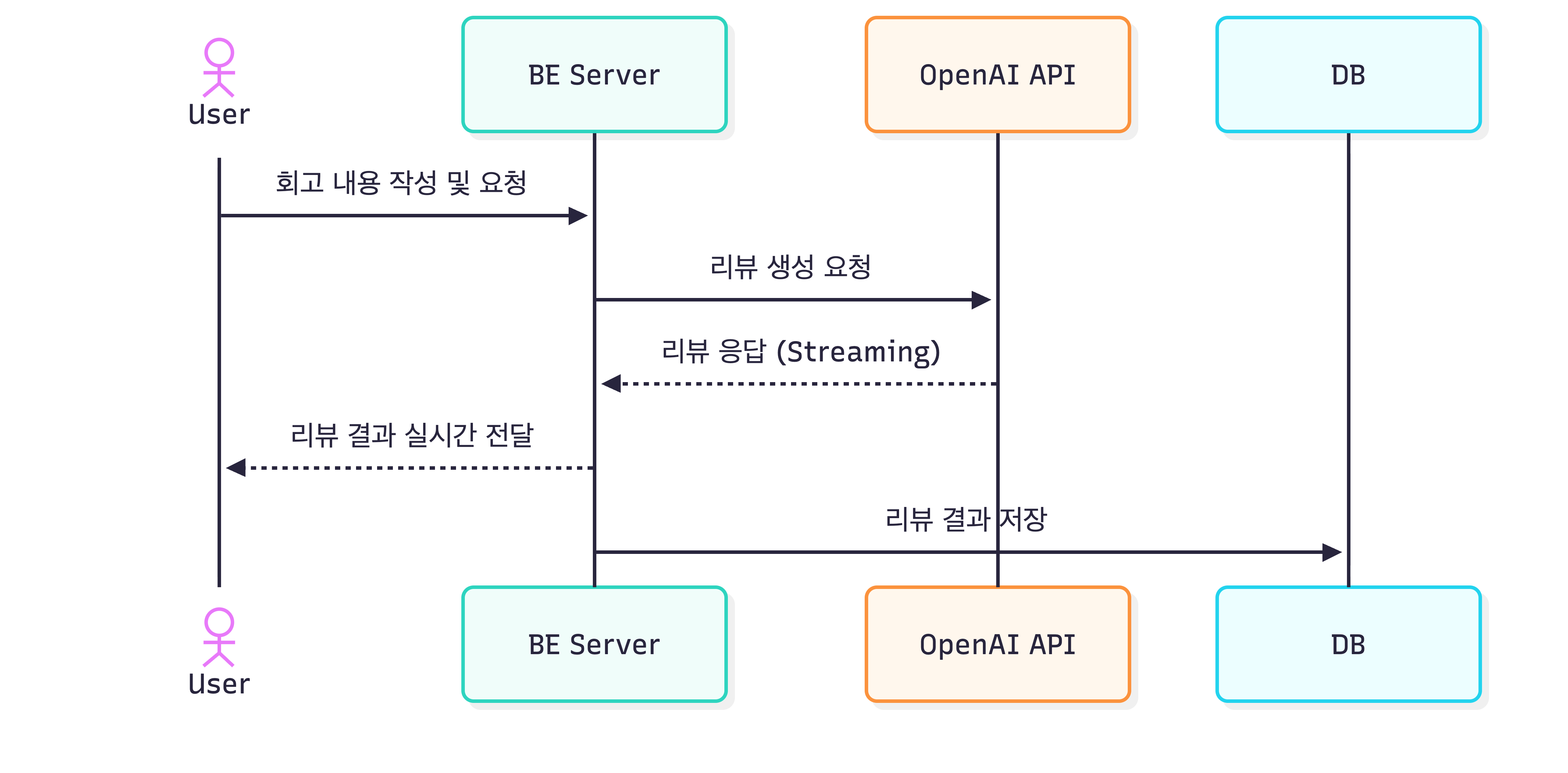
기능은 다음과 같은 순서로 진행되는 시나리오 였습니다.
- 사용자 회고작성
- BE 서버 전송
- OpenAI 호출
- 스트리밍
- Database 저장
기본적으로 SSE 토큰 스트리밍을 받을때 REST 기반의 HTTP 통신이 아닌 SSE(Server Sent Event)를 통신을 통해 API 서버로 단방향 비동기로 토큰을 수신했습니다.
이때 ChatClient는 해당 응답을 Flux형태로 리턴합니다. (Flux 자료구조)
Flux는 데이터를 시간에 따라 비동기적으로 흘려보내는 Reactive Streams 기반의 논블로킹 데이터 스트림입니다. 때문에 MVC 구조에서 사용하는 것은 권장되지 않습니다.
🧑💻 초기 구현
MVC 기반 서버에서 ChatClient를 통해 받은 응답을 SSE로 스트리밍하는 기능을 개발한 코드입니다.
[ReviewService.java]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
@Slf4j
@Service
@RequiredArgsConstructor
public class ReviewService {
private final OpenAiChatModel openAiChatModel;
private final ReviewRepository reviewRepository;
private final SecurityUtil securityUtil;
private final EncryptionUtil encryptionUtil;
private final DataSource dataSource;
@Value("${prompt.sora-type.T}")
private String promptAsT;
@Value("${prompt.sora-type.F}")
private String promptAsF;
/**
* todo : Review Entity 생성 후 저장
* @param req : 소라 회고 리뷰 요청
* @return : 소라 응답
*/
public Flux<String> requestSora(SoraReviewReq req){
Message userMessage = new UserMessage(req.getBody());
SystemPromptTemplate systemPromptTemplate;
FeedbackType requestType = req.getType();
if(requestType.equals(FeedbackType.FEELING)){
systemPromptTemplate = new SystemPromptTemplate(promptAsF);
}
else{
systemPromptTemplate = new SystemPromptTemplate(promptAsT);
}
Message systemMessage = systemPromptTemplate.createMessage();
// 전체 응답을 저장할 StringBuilder
AtomicReference<StringBuilder> fullResponse = new AtomicReference<>(new StringBuilder());
return openAiChatModel.stream(userMessage, systemMessage)
.doOnNext(response -> {
fullResponse.get().append(response); // 전체 응답 누적
})
.doOnComplete(() -> {
// 스트림 완료 시 누적된 응답을 데이터베이스에 저장
saveToDatabase(fullResponse.get().toString()).subscribe();
});
}
private Mono<Void> saveToDatabase(String fullResponse) {
/**
DB 저장 로직 생략
*/
return Mono.empty();
}
}
[ReviewController.java]
1
2
3
4
5
6
7
8
9
10
11
12
13
@RestController
@RequiredArgsConstructor
public class ReviewController {
private final ReviewService reviewService;
@PostMapping(value = "/test/api/request/review", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> requestSora(@RequestBody SoraReviewReq req) {
Flux<String> feedback = reviewService.requestSora(req);
return feedback;
}
}
위 코드 구현은 2가지 문제점이 있었습니다.
🤔 문제점 - 1
Flux는 Reactor기반의 Webflux 프로젝트에서Netty Event Loop를 사용했을때 효율적이고 Reactor Context로 컨텍스트 유지가 가능합니다.
하지만 위 처럼 MVC 기반의 프로젝트에서 반환하게 되면, Async Thread pool을 사용하긴 하지만 Context 유지가 되지 않아서 SSE 이후 저장하는 과정에서 Security Context 유지가 안되서 AuthenticationPrincipal 을 가져오는데 문제가 있었습니다.
또한 SecurityContext 내용을 수동으로 파라미터로 전달한다고 해도 DB 커넥션풀이 생성만되고 반납되지 않는 문제가 발생했습니다.
doOnComplete() 수행시 같은 라이프 사이클안에서 관리되지 않고 비동기로 수행되기 때문에 트랜잭션에 묶일 수 없었습니다.
🤔 문제점 - 2
MVC 기반에서 SSE 연결을 하면 Tomcat worker thread는 반환되지만 연결 유지를 위한 Servlet AsyncContext 컨텍스트는 스트리밍이 종료될때까지 연결을 점유합니다.
연결 개수만큼 AsyncContext가 생성됩니다. 100개의 연결이 있으면 100개가 생성됩니다. AsyncContext와 같은 무거운 요청 상태가 지속적으로 증가하면 GC 부담이 커질 것으로 예상되었습니다.
AsyncContext = ServletRequest + Response + buffer + 관리 객체
동시접속자 수가 늘어질수록 MVC는 동시 접속자가 증가하면 비동기 처리·응답 전송·타임아웃 관리 등을 위해 내부적으로 스레드 풀이 확장되며, 결과적으로 스레드 수 증가를 피할 수 없습니다.
만약 밤시간과 같이 일기를 쓰는 사용자가 붐비는 시간에 동시접속자 수가 maxThreads 보다 많아질 경우 서버가 특정 임계점에서 서버가 뻗는 문제가 발생할 것으로 예상되었습니다.
개선
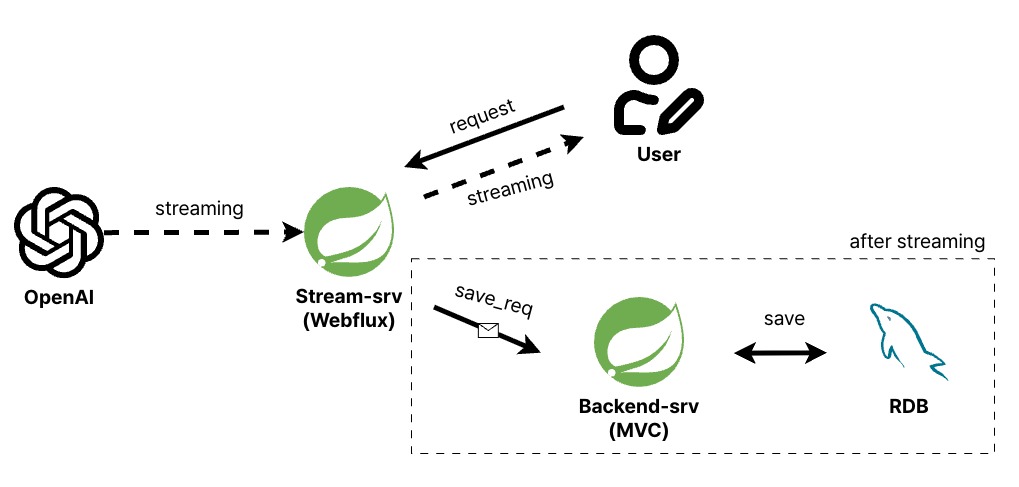
admin 모듈을 추가하여 프로젝트를 멀티모듈 아키텍처로 전환하는 과정에서 webflux로 함께 분리하며 Streaming 관련 기술부채를 해소하고자 했습니다.
webflux 모듈을 추가하고 토큰 스트리밍 요청은 모두 streaming 서버에서 처리하도록 기능을 분리했습니다.
🤔 저장 처리에 관한 고민
AI의 리뷰가 완료되면 DB로 저장하는 과정이 필요했는데 기존 JPA, JDBC같은 블로킹 서비스와 함께 쓰는 것은 Webflux에서 권장하지 않습니다.
WebFlux는 완전 비동기/논블로킹 스택이기 때문에, 블로킹 I/O를 섞으면 non-blocking의 장점을 살리기 여럽기 때문입니다.
R2DBC라는 JDBC를 대체하기 위한 대안이 있긴 했지만 기존 @Transactional과 다른 패러다임과 러닝 커브로 인해서 도입하지 않았습니다.
대신, 기존 MVC 서버에서 저장기능은 유지하고 streaming 서버에서 토큰 스트리밍이 끝나면 기존 서버로 저장요청을 보내는 구조로 개발했습니다.
⌨️ 코드
[SoraService.java]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
@Slf4j
@Service
@RequiredArgsConstructor
public class SoraService {
private final OpenAiChatModel chatClient;
private final WebClient webClient;
private final JwtUtil jwtUtil;
private final ObjectMapper objectMapper;
@Value("${prompt.sora-type.T}")
private String promptAsT;
@Value("${prompt.sora-type.F}")
private String promptAsF;
@Value("${sora.srv.url}")
private String appServer;
/**
* open-ai 스트리밍 메서드
*
* @param req
* @return
*/
public Flux<ReviewRes> streamReview(SubmitReq req, String token) {
if (token == null || !jwtUtil.validateToken(token) || jwtUtil.isExpired(token)) {
throw new ResponseStatusException(HttpStatus.UNAUTHORIZED, "Unauthorized");
}
String username = jwtUtil.getUsername(token);
String prompt = (req.getType() == FeedbackType.FEELING ? promptAsF : promptAsT)
.replace("{name}", username) + "\n" + req.getBody();
AtomicReference<StringBuilder> bufferRef = new AtomicReference<>(new StringBuilder());
return chatClient.stream(prompt)
.doOnNext(text -> bufferRef.get().append(text))
.index()
.map(tuple -> ReviewRes.builder()
.seq(tuple.getT1().intValue())
.value(tuple.getT2())
.build())
.doOnComplete(() -> {
String feedback = bufferRef.get().toString();
sendToServer(req, feedback, token);
});
}
/**
* 서버에 리뷰 저장
*
* @param req
* @param feedback
* @param token
*/
private void sendToServer(SubmitReq req, String feedback, String token) {
SaveReq saveReq = new SaveReq(req.getBody(), req.getType(), req.getReviewDate(), feedback);
webClient.post()
.uri(appServer)
.contentType(MediaType.APPLICATION_JSON)
.header(HttpHeaders.AUTHORIZATION, "Bearer " + token)
.bodyValue(saveReq)
.retrieve()
.bodyToMono(Void.class)
.subscribe();
}
}
AtomicReference란?
- 여러 쓰레드가 동시에 같은 객체를 참조할 때 사용할 수 있는 자료구조
- 멀티 스레딩 환경에서도 원자성을 보장하여 접근할 수 있게함
Flux 스트리밍 중에 리뷰 문자열을 안전하게 누적하고, 스트림 완료 시 최종 결과를 한 번만 사용하기 위해서 AtomicReference를 버퍼처럼 사용했습니다.
[SoraController.java]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@Slf4j
@RestController
@RequiredArgsConstructor
public class SoraController {
private final String BEARER_TOKEN = "Bearer ";
private final SoraService soraService;
@PostMapping(value = "/stream/review",
consumes = MediaType.APPLICATION_JSON_VALUE,
produces = MediaType.TEXT_EVENT_STREAM_VALUE
)
public Flux<ReviewRes> streamReview(@RequestBody SubmitReq req, ServerHttpRequest request) {
String authHeader = request.getHeaders().getFirst(HttpHeaders.AUTHORIZATION);
String token =
(authHeader != null && authHeader.startsWith(BEARER_TOKEN)) ? authHeader.substring(BEARER_TOKEN.length()) :
null;
return soraService.streamReview(req, token);
}
}
성능 측정
측정도구
SSE 성능 측정을 위해서 k6 라는 툴을 사용했습니다.
JMeter는 톰캣 기반이고