(DB) RDB unique 어떻게 동작하는가
RDB unique key는 어떻게 동작하는가
Database 대해서 공부한 내용을 정리한 글입니다.
Unique 제약 조건의 동작 방식에 대한 내용입니다.
Unique key란
RDB에서
unique란 말 그대로 테이블이나 인덱스에 중복된 값을 2개이상 가질 수 없다는 뜻입니다.. “중복을 DB 레벨에서 차단하기 위한 인덱스 제약(constraint)”라고 할 수 있습니다.즉 인덱스(B-Tree)이지만 제약조건이고 (중복된 데이터가 없기 때문) 제약 조건이지만 구현은 인덱스로 되어있습니다. Real MySQL 책에서도 인덱스 챕터에서 소개합니다.
MySQL에서는 인덱스 없이 UNIQUE 제약조건을 설정할 수 없다.
unique의 지정 방법
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
CREATE TABLE user_info (
id BIGINT AUTO_INCREMENT,
email VARCHAR(25) UNIQUE, -- email 컬럼에 중복 불가 제약조건
)
CREATE TABLE user_info (
id BIGINT AUTO_INCREMENT,
email VARCHAR(25) NOT NULL UNIQUE, -- NULL 허용 안하는 UNIQUE
)
CREATE TABLE user_info (
id BIGINT AUTO_INCREMENT,
email VARCHAR(25),
name VARCHAR(25),
UNIQUE(email, name) -- 복합 UNIQUE (email, name ) 조합으로 중복 X
)
ALTER TABLE users
ADD CONSTRAINT uk_users_email UNIQUE (email); -- ALTER 문으로도 가능 (별칭 지정)
CREATE UNIQUE INDEX uk_users_email -- 결국 인덱스라서 다음과 같이 INDEX로 선언 가능
ON users (email);
unique 읽기
unique key는 결국 인덱스이기 때문에 읽기도 B-Tree를 사용하는 다른 인덱스와 다르지 않다.
때문에 일반 일반적으로 인덱싱한 컬럼에 대해서 물리적으로 B-Tree 탐색 → row 접근하는 방식은 같다.
직접 unique와 constraint를 조회해봤습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
create table user_info (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(25) NOT NULL UNIQUE,
height INT,
INDEX index_of_height (height)
);
-- 둘이 똑같은 인덱스 접근 방식을 사용
select * from user_info where email = 'user1';
select * from user_info where height = 185;
그렇다면 EXPLAIN도 같은 실행계획을 출력할까요? 확인해봅시다.
EXPLAIN 실행 결과
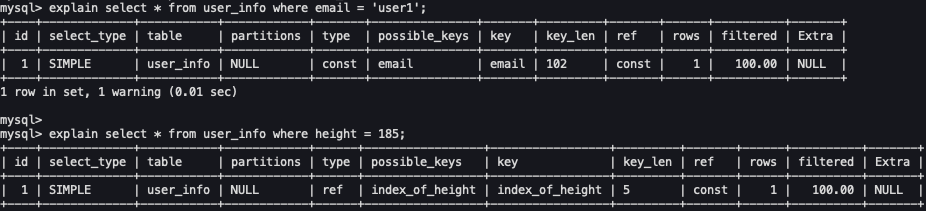
실행 계획 정리
| height | ||
|---|---|---|
| column 속성 | unique constraint | indexing |
| 실행계획 type | const | ref |
어라 type값이 다르다..!
email은 const type입니다. unique 제약 조건으로 규칙상 1건 이상 조회될 수 없기 때문에 optimizer가 단일 조회(const)를 한 것입니다.
하지만 height는 단순 인덱싱이므로 1개만 조회될 거라는 보장이 없기 때문에 ref 타입으로 실행됩니다.
만약 기존에 인덱싱된 컬럼 중 값의 중복이 없는 경우라면 unique 제약조건이 읽기 성능이 더 빠른 const 타입으로 실행되기 때문에 빠른조회가 필요하다면 unique 제약 조건을 고려해볼만 합니다.
Unique 쓰기
당연하게도 위에서 설명했듯이 unique는 인덱싱 되어 있기 때문에 당연히 쓰기 속도가 느립니다.
그런데 추가로 unique는 중복이 허용되지 않으므로, 쓰기전에 해당 값이 존재하는지 인덱스에서 탐색하는 과정을 거칩니다.
이때 중복을 검사하는 동안 DB에 LOCK이 걸립니다. UNIQUE를 사용할때 Dead Lock이 발생하는 원인중 하나 입니다.
하지만 이 과정을 거치기 때문에 중복에 대한 정합성을 안전하게 유지할 수 있습니다.
중복 데이터 Write 예제
1
2
3
4
5
6
7
8
9
10
11
mysql> select * from user_info where email='user1';
+----+-------+--------+
| id | email | height |
+----+-------+--------+
| 1 | user1 | 172 |
+----+-------+--------+
1 row in set (0.00 sec)
mysql> INSERT INTO user_info value(20, 'user1', 187);
ERROR 1062 (23000): Duplicate entry 'user1' for key 'user_info.email'
위처럼 중복된 데이터를 쓰기하면 Duplicate entry 에러가 발생하는 것을 알 수 있습니다.
</br>
다음은 unique key와 일반 인덱싱의 쓰기 작업 차이입니다.
1. 일반 INDEXING 쓰기 작업
- PK 인덱스에 삽입
- secondary index에 값 추가
- 중복 검사 없음
- 끝
2. UNIQUE KEY 쓰기 작업
- PK 인덱스에 삽입
- UNIQUE index에 삽입
- 같은 key가 이미 있는지 탐색 (🔒LOCK )
- 있으면 에러 / 없으면 삽입
write 성능 측정 테스트
측정 환경
- 테스트 디바이스 : MacBook air M2
- docker-compose에 메모리 및 cpu 제한
1
2
3
4
5
6
services:
mysql:
image: mysql:8.0
container_name: study-mysql
mem_limit: 500m # ram 설정
cpus: 1.0 # cpu 설정
테스트 table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- 일반 인덱싱
CREATE TABLE t_normal (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(50),
INDEX idx_email (email)
);
-- UNIQUE KEY 설정
CREATE TABLE t_unique (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
email VARCHAR(50),
UNIQUE INDEX uk_email (email)
);
다음과 같은 stored procedure로 50만개 Insert를 발생시켜 실행을 해봤습니다.
- mysql 캐싱을 제거하기 위해 실행전 docker restart를 모두 진행했습니다. (
GPT가 짜줬습니다)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
DELIMITER $$
CREATE PROCEDURE insert_normal(IN cnt INT) -- unique 테이블도 동일한 프로시저 생성함
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i <= cnt DO
INSERT INTO t_normal (email)
VALUES (CONCAT('user', i));
SET i = i + 1;
END WHILE;
COMMIT;
END$$
DELIMITER ;
일반 Index 삽입 수행

Unique key 삽입 수행

약 2.5초 정도 시간 차이가 발생했습니다!
empty table에서 수행했고 insert되는 데이터가 작았기 때문에 다음과 큰 차이가 있진 않았지만 기존에 저장되어 있는 row수가 커질수록 중복 검사시 탐색 비용이 커지므로 더 오랜 시간이 걸릴거라고 예상해볼 수 있습니다.
대규모 트래픽이 발생하여 쓰기가 많이 발생하거나 Batch 작업과 같은 대규모 쓰기 작업에서는 Unique key의 사용을 잘 고려해야 하는 것을 알 수 있습니다.
중복 탐색 Lock 동작
기본적으로 MySQL에 추가적인 격리수준을 조정하지 않으면 다음과 같은 Lock이 발생합니다.
Record Lock
- 이미 같은 값이 있으면 그 레코드에 Record Lock
Gap Lock / Next-Key Lock
- 같은 값이 없을 경우에도 “없다는 사실을 보장하기 위해” 해당 값이 들어갈 gap을 잠금
//Todo : Dead Lock 테스트 해보기
primary key vs unique key
생각해보면 Primary key도 테이블에서 유일하게 1개만 존재해야 하고 UNIQUE 인덱싱도 중복을 허용하지 않습니다.
하지만 둘의 의미는 본질적으로 다릅니다.
- PK는 각 행을 고유하게 식별하는데 사용합니다. UNIQUE는 복합으로 조건을 걸 수 있습니다. ( => 행이 유일하다는 조건에서 벗어납니다.)
- 하지만 unique key는 NULL 값을 허용합니다. NOT NULL을 붙이지 않는 이상 NULL이 삽입될 수 있습니다.
MySQL에서 NULL은 값이 아니라 “값이 없음”이기 때문에 = 비교가 불가능하고, 그 결과 UNIQUE 제약에서도 중복으로 판단되지 않습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
mysql> CREATE TABLE test (
-> email VARCHAR(100) UNIQUE
-> );
Query OK, 0 rows affected (0.08 sec)
mysql> INSERT INTO test VALUES (NULL);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO test VALUES (NULL); -- NULL을 총 2번 삽입이 가능
Query OK, 1 row affected (0.01 sec)
mysql> SELECT NULL = NULL AS result; -- NULL은 비교 연산자의 대상이 아님
+--------+
| result |
+--------+
| NULL |
+--------+
1 row in set (0.01 sec)
PK와 UK의 차이 정리
| 구분 | PRIMARY KEY | UNIQUE |
|---|---|---|
| 중복 허용 | ❌ | ❌ |
| NULL 허용 | ❌ | ⭕ (여러 개 가능) |
| 테이블당 개수 | 1개 | 여러 개 가능 |
| 클러스터드 인덱스 | ⭕ (InnoDB) | ❌ |